
Azure Data Factory Training in Hyderabad
With
Certification & 100% Placement Assistance
Online, Offline & Hybrid Training modes | 2.5 Months | Real Time Projects
Join Azure Data Factory Training in Hyderabad and learn from industry experts. Build strong skills in creating and managing data pipelines, automating ETL and ELT workflows, designing mapping and wrangling data flows, scheduling with triggers, and monitoring pipelines. Work on real projects, prepare for certification, and get the confidence to start your career in data integration and cloud data workflows in Hyderabad and across India.
Table of Contents
ToggleAzure Data Factory Course in Hyderabad
Next Batch Details
| Trainer Name | Mr. Dinesh |
| Trainer Experience | 9+ Years of Real Time Experience |
| Next Batch Date | 25th Feb 2026 9:00 AM IST |
| Training Modes: | Online, classroom and Hybrid modes available |
| Course Duration: | 2 to 2.5 Months |
| Call us at: | +91 81868 44555 |
| Email Us at: | brollyacademy@gmail.com |
| Demo Class Details: | ENROLL FOR FREE DEMO CLASS |
Why Brolly Academy is the Best Training Institute in Hyderabad?
12,000+
Placement Rate
300+
Google Reviews
4.8
Ratings
20,000+
Students Trained
2.5 Months
Duration
Modes
Classroom, Online, Hybrid
Fee Range
Affordable Fee Range
50+
Projects Completed
Why Choose Brolly Academy for Azure Data Factory Training in Hyderabad?
- Updated 2026 ADF Curriculum covering data pipelines, ETL/ELT workflows, triggers, integration runtimes, mapping and wrangling data flows, and monitoring dashboards.
- Expert Trainers with 9+ Years of Azure Experience, guiding you step by step in real business use cases.
- Practical Training with Live Projects including pipeline automation, data migration, and hybrid cloud integrations.
- Placement Assistance and Internships to help you get real work experience and job confidence.
- Practical Training in Azure Data Factory Labs with direct access to pipelines, triggers, and runtime configurations.
- Complimentary Classes on SQL & Azure Basics to strengthen your foundation before working on ADF.
- Training in English & Telugu for easy understanding and better comfort during Azure Data Factory classes.
- Lifetime Access to ADF Class Recordings and Study Material so you can revise anytime after the training.
- Daily Mentor Guided Lab Sessions to practice building and debugging ADF workflows.
- You will get Azure Data Factory Course Completion Certificate from Brolly Academy.
- Industry Projects in Finance, Retail, and Healthcare covering data flow automation and cloud based integrations.
- Fast Track Batches for working professionals.
- 360° ADF Coverage including orchestration, monitoring, pipeline scheduling, and integration with Azure SQL, Synapse, and Data Lake.
- Multiple Modes of Learning: Online, Offline, and Hybrid classes available.
- Post Placement Support with project guidance and real time problem solving after you join your job.
- Certification Guidance for Microsoft Azure Data Factory and related certifications through the Microsoft Learn platform.
Azure Data Factory Course Curriculum
- Spark Architecture and Concepts
- PySpark DataFrames and SQL
- ETL with PySpark
- Aggregations, Joins, Transformations
- Practice: Build a data pipeline with PySpark
6. Azure SQL Database
7. Table Creation, Indexing, Procedures
8. Cosmos DB (NoSQL)
9. Partitioning and Consistency Models
10. Practice: Query and manage data in Azure SQL and Cosmos DB
11. Synapse Studio Overview
12. Serverless vs Dedicated SQL Pools
13. Integration with Azure Data Lake
14. Query Performance Tuning
15. Practice: Create an analytics workflow with Synapse and Data Lake
16. ADF Pipelines: Structure and Triggers
17. Data Flows and Copy Activity
18. Linked Services and Integration Runtime
19. Monitoring and Debugging
20. Practice: Move and manage data with ADF Pipelines
21. Databricks Notebooks and Clusters
22. Delta Lake for Storage and Updates
23. Integration with ADF
24. ML Pipelines using PySpark in Databricks
25. Practice: Explore data and train models in Databricks
26. Azure Stream Analytics Basics
27. Access Control with Azure Active Directory
28. Key Vault Integration
29. Practice: Build a live dashboard with Stream Analytics
30. Git and GitHub Basics
31. Branching, Commits, Collaboration Workflow
32. Practice: Manage data pipeline code with Git
33. Joins, Aggregations, Window Functions
34. Stored Procedures and Triggers
35. Performance Tuning Techniques
36. Practice: Solve SQL query challenges and optimize performance
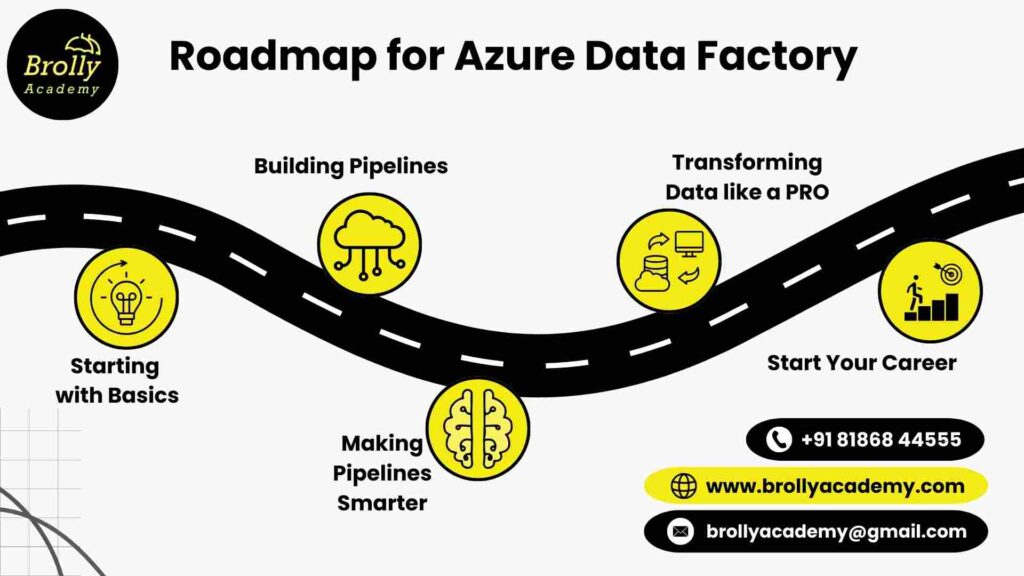
Azure Data Factory Training In Hyderabad - Roadmap
- Learning Azure Data Factory at Brolly Academy is not just about theory, it is a practical journey.
- We start with the basics and gradually move into advanced topics so that by the end, you are confident in working with pipelines, data flows, and real time projects.
- Each step is carefully designed to connect with the next step, making your learning experience smooth and practical.
01
Step 1: Starting with Basics
- Learn what Azure Data Factory is and how it simplifies data management
- Learn how the ADF dashboard and menus work
- Learn how to connect ADF with a data source
- Create your first simple pipeline to move data
- Know the role of Integration Runtime in moving data
02
Step 2: Building Your First Pipelines
- Design structured ETL and ELT workflows in ADF
- Work with datasets, activities, and parameters for dynamic pipelines
- Automate tasks using triggers and schedules
- Learn how to connect ADF with Azure SQL, Data Lake, and Blob Storage
- Practice building reusable components for efficiency
03
Step 3: Making Pipelines Smarter
- See how your pipelines are running in the dashboard
- Fix pipeline issues using simple troubleshooting steps
- Set up alerts to get updates on your pipelines
- Optimize workflows for faster and more reliable data processing
- Handle errors in pipelines without breaking the workflow
04
Step 4: Transforming Data Like a Pro
- This is where you go deeper into real data processing.
- You will use Azure Databricks notebooks and clusters, and Spark to work with large data.
- You will also learn about Delta Lake for safe storage and connect Data Factory with Databricks.
- To make it real, you will work on projects like retail sales reports and IoT dashboards.
05
Step 5: Start your Career
- Do complete projects that connect ADF, Synapse, and Data Lake
- Work on industry examples in finance, retail, and healthcare
- Prepare with practice questions for Microsoft certification exams
- Get personalized support for resume building and interviews
- Post training career guidance and job assistance is provided if needed
Azure Data Factory overview in Telugu
What is Azure Data Factory?
- Azure Data Factory (ADF) is a cloud tool from Microsoft that helps move and manage data.
- It works like a pipeline system that carries data from one place to another.
- Companies use it to bring data from different sources like databases, files, and apps into one location.
- ADF can clean, change, and prepare data so it is ready for use.
- It works with both time based data transfers and live data updates
- You can create automated workflows that run without manual work.
- It connects easily with other Azure services like SQL, Synapse, and Data Lake.
- ADF has built in tools to monitor, debug, and fix issues in data pipelines.
- It helps organizations save time by automating repetitive data tasks.
- ADF is easy to use since you can build pipelines with drag and drop instead of coding
- ADF is used in industries like banking, healthcare, retail, and IT to handle large amounts of data.
- In simple terms, ADF makes it easier to collect, organize, and prepare data for reporting, analytics, or machine learning.
Why is Azure Data Factory Important?
- Every business today is collecting data from websites, apps, customer records, or devices.
- But the real challenge is moving all that data to one place and making it ready for use. That’s where Azure Data Factory comes in.
- Microsoft says ADF connects with more than 90 different sources and handles millions of runs every single day.
- This shows how trusted it has become for companies that want to keep their data flowing without delays.
Reason | How it is Important |
You can connect with almost any data source | ADF helps you collect data from the cloud, your local systems, and other apps, and shows it all in one place |
You do not have to do things manually | Instead of repeating the same data tasks every day, ADF can run them for you on time or whenever something new happens. This saves effort and reduces mistakes. |
You do not need to be a coding expert | ADF gives you drag and drop tools along with options for coding. That means it works well for beginners and also for advanced users. |
You always know what is happening | With built in monitoring, ADF shows if your pipelines are working fine. You can spot issues early and keep your data flowing without worry. |
You can move data the way you want | Some businesses need fresh data every second while others just need daily updates. ADF supports both so you can choose what works best. |
It grows with your business | ADF adjusts to your needs and works with any size of data |
It fits perfectly with other Azure tools | ADF connects smoothly with Azure SQL, Synapse, Data Lake, and Power BI so that you can build complete end to end solutions. |
It helps your career | Cloud skills are in demand, and ADF is one of the most asked skills in data jobs. Learning it puts you ahead in the market. |
Where is Azure Data Factory Used?
- Shopping and Online Stores : Big shops and websites use ADF to collect details of what people buy, what is left in stock, and what customers like. This helps them keep Stock up to date and give better offers.
- Banks and Money : Banks use ADF to safely move money records and keep them ready for checks and reports. It makes the work faster and less chances for mistakes.
- Hospitals and Healthcare : Hospitals use ADF to bring patient reports, test results, and other health data into one place. This way, doctors can see everything clearly and treat patients quickly.
- Moving Old Data to the Cloud : When companies shift from old computers to the cloud, ADF helps copy and clean the data. It makes the process easy without stopping daily work.
- Reports for Business : Companies use ADF to prepare neat reports for sales, staff, and other work. It changes rough data into clean numbers that managers can understand.
- Different Systems Talking Together : Sometimes data is kept in many places like company servers, apps, or other clouds. ADF connects all of them so the data is always ready and up to date.

Azure Data Factory Training in Hyderabad
Benefits of the Course
- Joining this course is not just about attending classes. It is about learning skills that companies use every day.
- At Brolly Academy, we make sure you get practical knowledge, hands on training, and career support. Here is what you gain :
1. Strong Basics in ADF
You will learn how Azure Data Factory works, including pipelines, datasets, and linked services, so you can start building from day one.
2. Real Pipeline Practice
You will design and run data pipelines, use triggers to automate them, and manage integration runtimes with real life scenarios.
3. Data Flow Skills
You will learn to use mapping and data preparation flows, which are tools in ADF that clean, join, and organize raw data so it becomes ready for reporting or analysis.
4. Monitoring and Debugging
The course shows you how to track pipelines, fix errors fast, and make sure everything runs smoothly with monitoring
5. End to End Project Exposure
You will work on projects that bring together ADF with Azure SQL, Synapse, and Data Lake, just like in real company setups.
6. Certification Ready
We train you with Microsoft exam patterns so you can attempt ADF related certifications with confidence.
7. Career Oriented Skills
The training covers important ADF tasks such as automation, data migration, and cloud workflows that companies want today
8. Flexible Learning Support
You will have recordings, notes, and mentor support so you can revise pipelines, data flows, and other tricky topics anytime.
9. Learn from Experts
Our trainers bring years of real experience in building pipelines, monitoring workflows, and automating data solutions, so you learn the shortcuts that are really useful.
Thinking of an Azure Data Factory Course in Hyderabad?
- Traditional Training
- Focuses mainly on theory with limited practice
- One way teaching with less student interaction
- Outdated syllabus that misses new ADF features
- Little or no exposure to real projects
- No certification support
- Limited learning material
- Language barriers for local learners
- No personal career help
- Learning ends with the course schedule
- Brolly Academy Training
- Practical learning with real projects and guided labs
- Interactive sessions with doubts cleared in class and after class
- Updated 2026 curriculum with pipelines, triggers, data flows, and monitoring
- Industry level projects in retail, banking, and healthcare
- Step by step guidance for Microsoft certification exams
- Lifetime access to recordings, notes, and updates
- Training in English and Telugu for easy understanding
- Placement assistance, resume tips, and interview practice
- Post placement support is provided.
Best Azure Data Factory Training Institute in Hyderabad
Meet Your Trainer
INSTRUCTOR
Dinesh
Azure Expert
9+ Years of Real Time Experience
About the instructor:
- Dinesh is the lead trainer for our Azure Data Factory Course in Hyderabad with over 9 years of experience in the cloud and data field. He has worked on real time projects using Azure Data Factory, Synapse Analytics, Databricks, Spark, SQL, and Python, giving him the skills to train students with practical knowledge that companies expect today.
- He has guided many learners in Hyderabad and across India to learn from basics to advanced Azure Data Factory Skills. Dinesh explains concepts in a simple way and uses real business cases like retail, IoT, and healthcare data projects. His teaching style connects classroom learning with what actually happens in the workplace.
- Under his guidance, you will not only gain skills in Azure Data Lake, pipelines, and big data tools, but also prepare for the Azure Data Factory certifications. Dinesh also supports students with resume building, interview practice, and placement guidance, making sure you are ready for data Factory jobs in Hyderabad and over country.

Azure Data Factory Course in Hyderabad
Skills you will develop after the Course
- Moving Data Easily : You will know how to transfer data from one place to another without errors.
- Building Workflows : You will learn to create step by step workflows that move and prepare data automatically.
- Working with Triggers : You will understand how to set triggers that start pipelines when you want them to run.
- Using Integration Runtime : You will learn how to use Integration Runtime to connect data across cloud and local systems.
- Cleaning and Shaping Data : You will practice turning messy data into clean and useful data for reports.
- Watching Your Pipelines : You will be able to monitor pipelines, check if they are running fine, and fix small issues.
- Handling Big Data : You will gain confidence in working with large amounts of data without slowing down the system.
- Connecting with Azure Services : You will see how ADF works smoothly with Azure SQL, Synapse, Data Lake, and other tools.
- Automating Tasks : You will learn how to reduce manual work by letting ADF run jobs on its own.
- Finishing Real Projects : You will complete end to end projects that show how ADF is used in banks, retail, and healthcare.
Azure Data Factory Classes in Hyderabad
capstone projects covered
1. Real Time Data Pipeline for E-Commerce Analytics
This project links an online store's data to a system that updates in real time. It tracks things like customer actions and sales as they happen, giving quick updates on how the business is performing.
2. Data Integration for Financial Reporting System
This project pulls data from different financial systems (like accounting software) and puts it into one place. This makes it easier for companies to generate financial reports and analyze their finances more effectively.
3. Azure Data Factory for IoT Data Processing
This project works with data from smart devices like sensors. It helps process all the data these devices create, storing it in a secure place and using it for things like monitoring systems or tracking performance.
4. Customer 360 View with ADF and Power BI Integration
This project brings together customer data from many places (like sales and support systems) into one view. It gives companies a complete picture of each customer and helps them understand their needs better, using visuals like charts and graphs in Power BI.
5. Machine Learning Model Deployment Pipeline
This project automates the process of training and deploying machine learning models. It helps improve things like predictions and automation by setting up a system that continuously updates and deploys the latest models.
6. Healthcare Data Integration for Predictive Analytics
This project connects and processes healthcare data from multiple sources, such as patient records and insurance information. It helps doctors and hospitals make better predictions and decisions based on this combined data, using advanced analytics tools.
What are the tools covered in Azure Data Factory Course?
Tools Covered












Azure Data Factory Training in Hyderabad
Course Fees
Video Recording
Rs 15000 9999
- Lifetime video access
- Basic to advanced level training
- 50+ recorded classes
- Capstone project
- Resume & interview support
- 100% placement assistance
- WhatsApp group access
Class Room Training
Rs 35000 29999
*** EMI option available***
- 2–2.5 months structured training
- Real time Azure Data Factory Experts (working pros)
- Real time projects
- One on one mentorship
- Monthly mock interviews
- Resume & interview guidance
- Soft skills training
- Dedicated placement officer
- Commute support (offline batches)
- WhatsApp support + group access
Online Course
Rs 30000 24999
*** EMI option available***
- Live interactive classes (flexible timings)
- 2–2.5 months duration
- Daily recorded sessions for revision
- Project environment from Day 1 until placement
- Weekly mock interviews
- Doubt clearing sessions
- 50+ sample resumes access
- WhatsApp group access
Azure Data Factory Course in Hyderabad
Placement Program
- Completing the Azure Data Factory course is the first step, but getting placed requires more than just learning the tools.
- This is why our placement program is designed to prepare you for the real job market, from building a strong resume to facing interviews with confidence.
- Here is how our placement program will guide you step by step:

Resume Building

Placement Training

Interview Questions

Realtime Live Projects

Get Offer Letter
Scheduling Interviews

Personality Development

Mock Interviews
- Resume Building: We help you prepare a clean and professional resume that highlights your skills and projects in the right way. Recruiters will see your strengths at first glance.
- Placement Training: You will get guidance on how the hiring process works, from applications to interviews, so you know exactly what to expect.
- Realtime Live Projects: Working on real projects gives you practical stories to share in interviews and the confidence to explain how you solved problems.
- Interview Questions: We share the questions that are often asked in interviews so you can be ready for them
- Mock Interviews: Practice makes perfect. We conduct mock interviews that feel like the real ones and give you feedback to improve
- Personality Development: Soft skills are also important as technical skills. We help you build confidence, communication, and the right attitude for professional growth.
- Scheduling Interviews: Our team connects you with companies, arranges interviews, and keeps you updated so you focus only on your performance.
- Get Offer Letter: The last step is receiving your offer letter and starting your career with full confidence, supported by our guidance throughout
What Our Students Say About Azure Data Factory Training in Hyderabad?
Testimonials
Azure Data Factory Course in Hyderabad
Student Community
Learning & Collaboration
Students share ideas, solve pipeline challenges together, and practice data flows in a team environment, making learning faster and smoother.
Access to Resources
You will have lifetime access to recordings, notes, and ADF practice labs, so you can revise pipelines, triggers, and workflows anytime.
Networking Opportunities
The community connects you with peers and professionals working on ADF, Synapse, and Data Lake, opening doors to job opportunities.
Mentorship from Experts
Industry experts guide you with real ADF project examples, from building pipelines to monitoring workflows, so you learn the way companies work.
Career Support
Our community shares interview questions, certification tips, and placement updates to help you stay prepared for real job roles.
Azure Data Factory Classes in Hyderabad
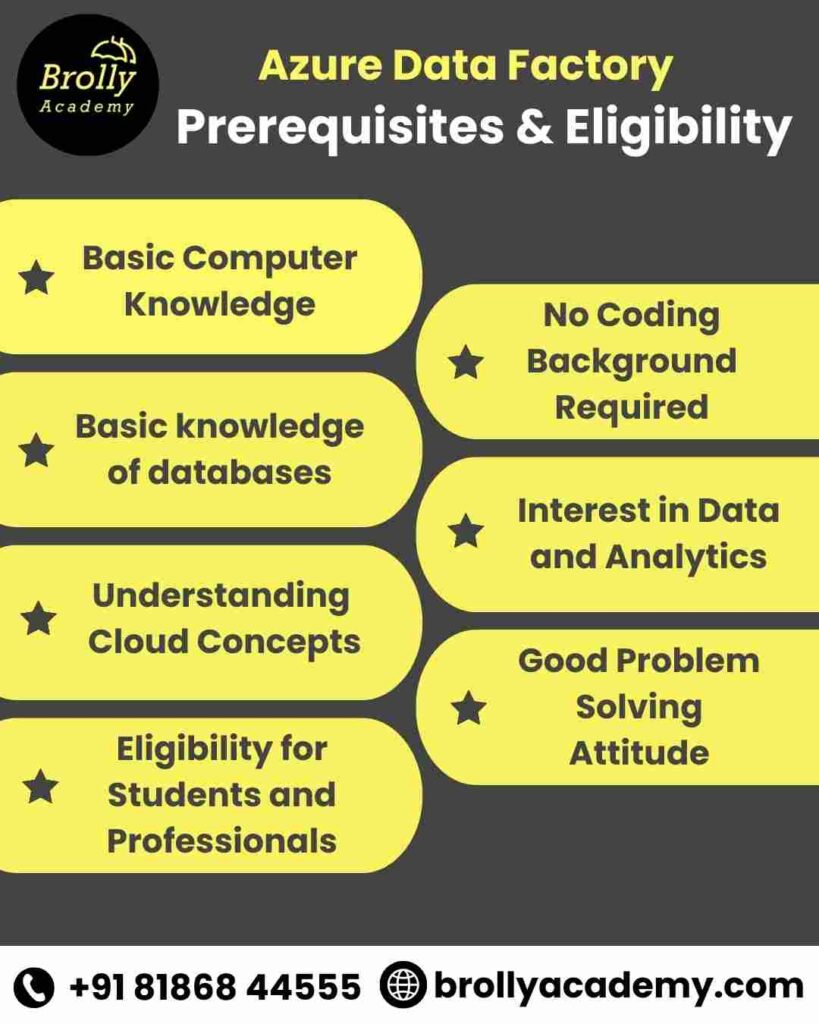
Pre-requisites & Eligibility
- Before starting any training, it is important to know the basic skills that will help you learn faster.
- Azure Data Factory is designed in a way that even beginners can start, but having some knowledge of databases, cloud, or data concepts makes the journey smoother. Here are the pre-requisites and eligibility points for our ADF classes:
- Basic Computer Knowledge – Anyone with a general understanding of computers and software can join the training.
- Basic knowledge of databases – Knowing simple SQL queries or understanding tables and rows will help you work with datasets and linked services.
- Understanding Cloud Concepts – A basic idea of how cloud platforms like Azure work will make it easier to connect services and build pipelines.
- Eligibility for Students and Professionals – Whether you are a fresher, IT professional, or someone looking to switch careers, you can enroll and learn ADF step by step.
- No Coding Background Required – ADF provides drag and drop tools for pipelines and data flows, so coding experience is not a must.
- Interest in Data and Analytics – If you are curious about how data is moved, cleaned, and prepared for reports, this course is a good fit for you.
- Good Problem Solving Attitude – ADF often involves finding smart ways to connect and clean data, so being open to solving problems will help you succeed faster.
Who Should learn Azure Data Factory Course in Hyderabad?
- Today, companies need experts who can move, clean, and manage data with ease.
- Learning Azure Data Factory gives you the exact skills that make you grow in career and open doors to better opportunities.
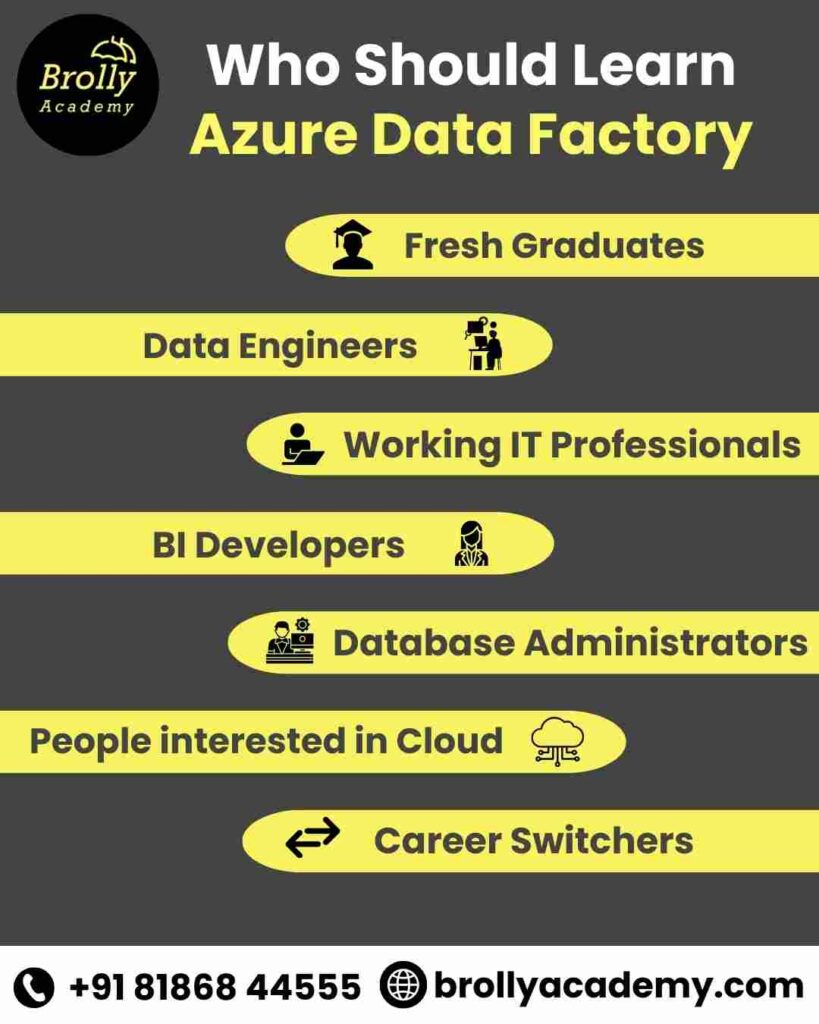
- Fresh Graduates – If you are a fresher looking to start a career in data or cloud, ADF provides the skills you need to start a strong career in data and cloud.
- Working IT Professionals – Professionals in software, support, or database roles can upgrade their skills with pipelines, triggers, and workflows to move into better roles.
- Data Engineers – If you already work with data, ADF helps you build stronger data pipelines and manage complex workflows with ease.
- Business Intelligence Developers – BI developers can use ADF to prepare clean data for Power BI and Synapse, improving the quality of dashboards and reports.
- Database Administrators– DBAs can learn ADF to automate data migration and integrate databases with cloud storage like Azure Data Lake.
- People interested in Cloud – Anyone interested in cloud computing can learn ADF to understand how Azure services connect and work together.
- Career Switchers – If you are planning to move into data or cloud from a different background, ADF is a beginner friendly tool to start with.
Azure Data Factory Jobs in Hyderabad for Freshers and Experienced
Career Opportunities

- Azure Data Engineer (Freshers and Experienced) - You will work with pipelines, triggers, and data flows in ADF to move and prepare data for everyday business use.
- Azure ETL Developer (Fresher & Experienced) - You will use ADF to pull data from different places, clean it with mapping data flows, and load it into systems like Azure SQL or Synapse.
- Azure Data Factory Developer (Fresher & Experienced) - This role is all about ADF where you create workflows, connect linked services, and keep an eye on pipelines.
- Azure Cloud Data Engineer (Experienced) - Here you connect ADF with Azure Data Lake, Synapse, and Databricks to manage big and even real time data.
- Azure Business Intelligence Developer(Freshers and Experienced) - In this role you prepare data with ADF so Power BI dashboards and business reports always show the right numbers.
- Database Administrator with Azure Data Factory Skills (Experienced) - As a DBA you can use ADF pipelines to move old databases into Azure and set up easy backups.
- Data Analyst with Azure Data Factory Skills (Freshers) - You can use ADF to clean and shape raw data before turning it into simple reports and insights.
- Azure Data Migration Specialist (Experienced) - This job is about moving data from older systems into Azure Data Lake or Synapse with the help of ADF pipelines.
Over 7000+ job openings available for Azure Data Factory in Hyderabad for freshers & Experienced
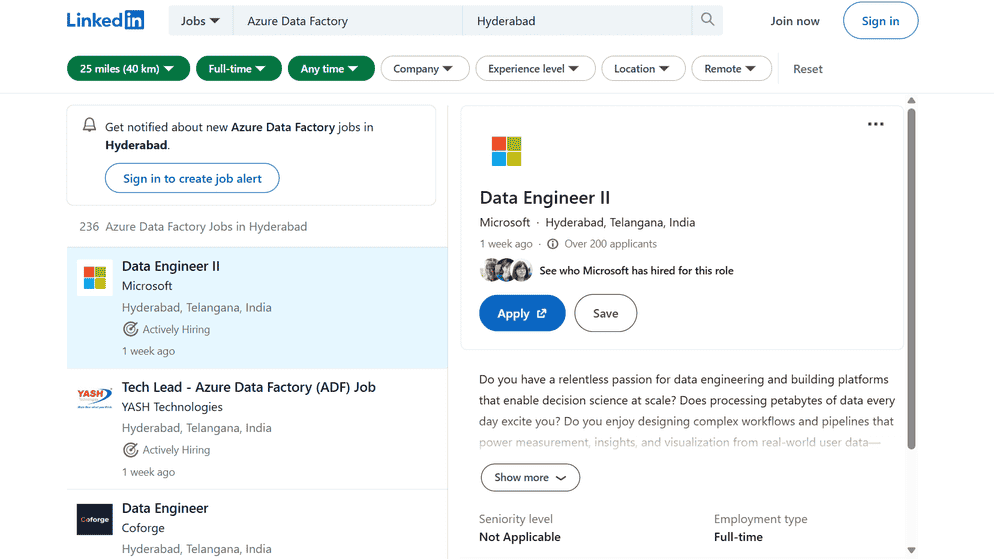
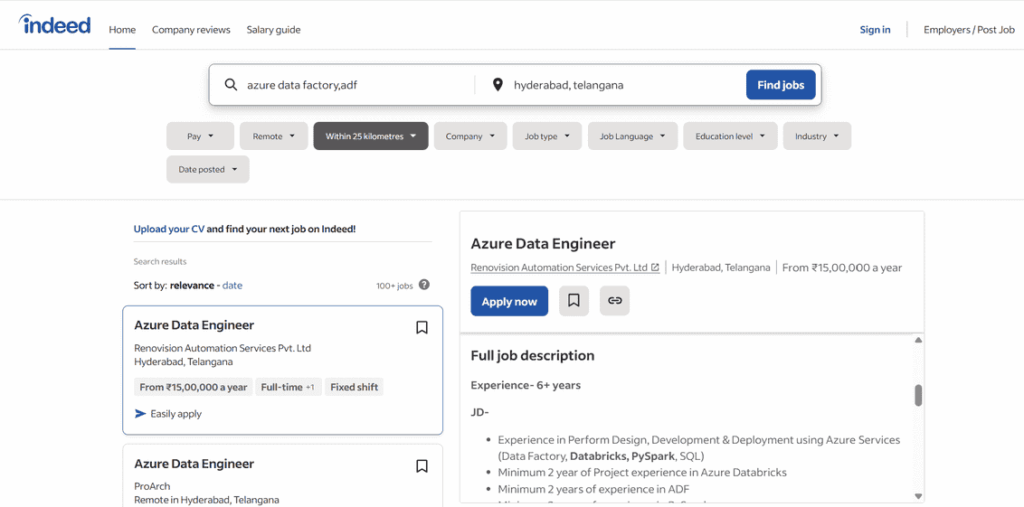
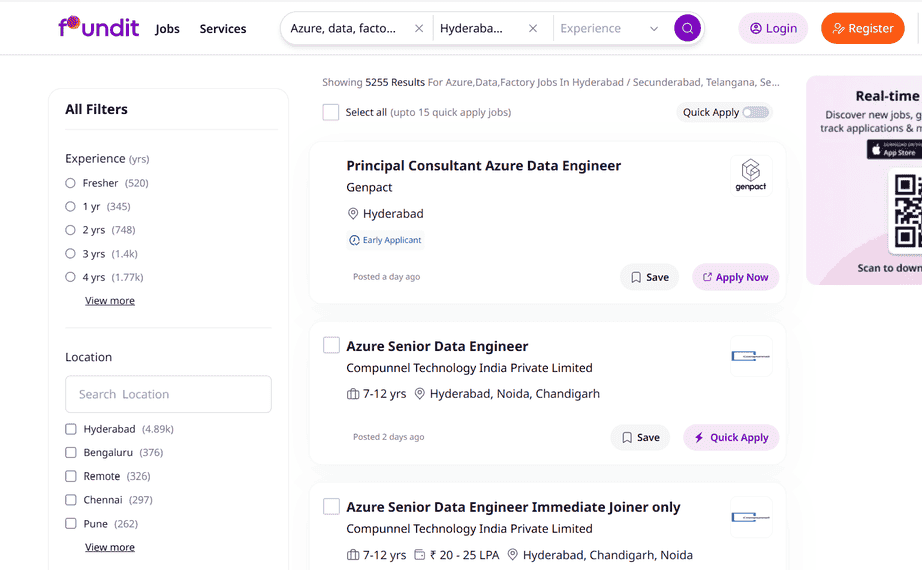
Azure Data Factory Salaries in Hyderabad – Latest Updates (2026)
Job Role | Entry Level (0–2 yrs) | Mid Level (3–5 yrs) | Experienced (6+ yrs) |
Azure Data Engineer | ₹5 – ₹8 LPA | ₹10 – ₹15 LPA | ₹18 – ₹28 LPA |
Azure ETL Developer | ₹4.5 – ₹7 LPA | ₹9 – ₹14 LPA | ₹16 – ₹25 LPA |
Azure Data Factory Developer | ₹5 – ₹8 LPA | ₹11 – ₹16 LPA | ₹20 – ₹30 LPA |
Azure Cloud Data Engineer | ₹6 – ₹9 LPA | ₹12 – ₹20 LPA | ₹25 – ₹35 LPA |
Azure Business Intelligence Developer | ₹4 – ₹7 LPA | ₹9 – ₹13 LPA | ₹15 – ₹24 LPA |
Database Administrator with ADF Skills | ₹4.5 – ₹7 LPA | ₹9 – ₹13 LPA | ₹16 – ₹24 LPA |
Data Analyst with ADF Skills | ₹3.5 – ₹6 LPA | ₹7 – ₹11 LPA | ₹12 – ₹20 LPA |
Azure Data Migration Specialist | ₹5 – ₹8 LPA | ₹10 – ₹15 LPA | ₹18 – ₹28 LPA |
Note : These are approximate ranges and may vary based on skills, company, and project complexity.
Companies Hiring for Azure Data Factory Professionals from Brolly Academy







Best Azure Data Factory Training Institute in Hyderabad with Placement
Our Achievements
Completed 45+ Batches
9+ Years of experience
567+ Students Placed
Pioneer in the Industry
Azure Data Factory Certification in Hyderabad.

- As more companies use Azure Data Factory for data integration and cloud projects, certifications are becoming more important.
- At Brolly Academy, we guide you through the entire certification journey.
- We provide exam preparation, practice tests, real time project support, and mock questions so you feel confident before taking the official Microsoft exam.
- Our trainers also share tips, project examples, and scenarios that reflect the type of questions you will face in the certification.
Course Completion Certificate
- After finishing the Azure Data Factory training, you will receive a Brolly Academy Course Completion Certificate.
- This certificate shows that you have experience in ADF tools like pipelines, triggers, mapping data flows, linked services, and monitoring dashboards through real projects.
- You can put it on your LinkedIn profile, resume, and job portals to get higher career opportunities in Hyderabad and throughout India.
- In today’s job market, certification is proof that your knowledge and skills are real.
- Companies in Hyderabad and across India give more value to candidates with Azure certifications.
- Because, it shows you can handle practical tasks like building pipelines, managing data flows, and moving data between systems.
- A certification that includes Azure Data Factory makes your resume stronger and helps you to be a high priority candidate when applying for jobs.
- Recruiters always use certifications as a quick way to shortlist profiles, especially for cloud and data roles.
- Certified professionals usually get better salary packages and grow faster in their careers compared to those without certifications.
- Azure Data Engineer Associate (DP-203)
- Azure Fundamentals (AZ-900)
- Azure Database Administrator Associate (DP-300)
- Power BI Data Analyst Associate (PL-300)
- Azure Solutions Architect Expert (AZ-305)
- Brolly Academy’s Course Completion Certificate
What is the Cost of Azure Data Factory Certification in Hyderabad?
Certification Name | Price (USD / Approx INR)* | Exam Time Limit / Duration | Passing Score |
Azure Data Engineer Associate (DP-203) | 120 minutes | ||
Azure Data Fundamentals (DP-900) | 120 minutes | ||
Azure Database Administrator Associate (DP-300) | |||
Power BI Data Analyst Associate (PL-300) | |||
Azure Solutions Architect Expert (AZ-305) |
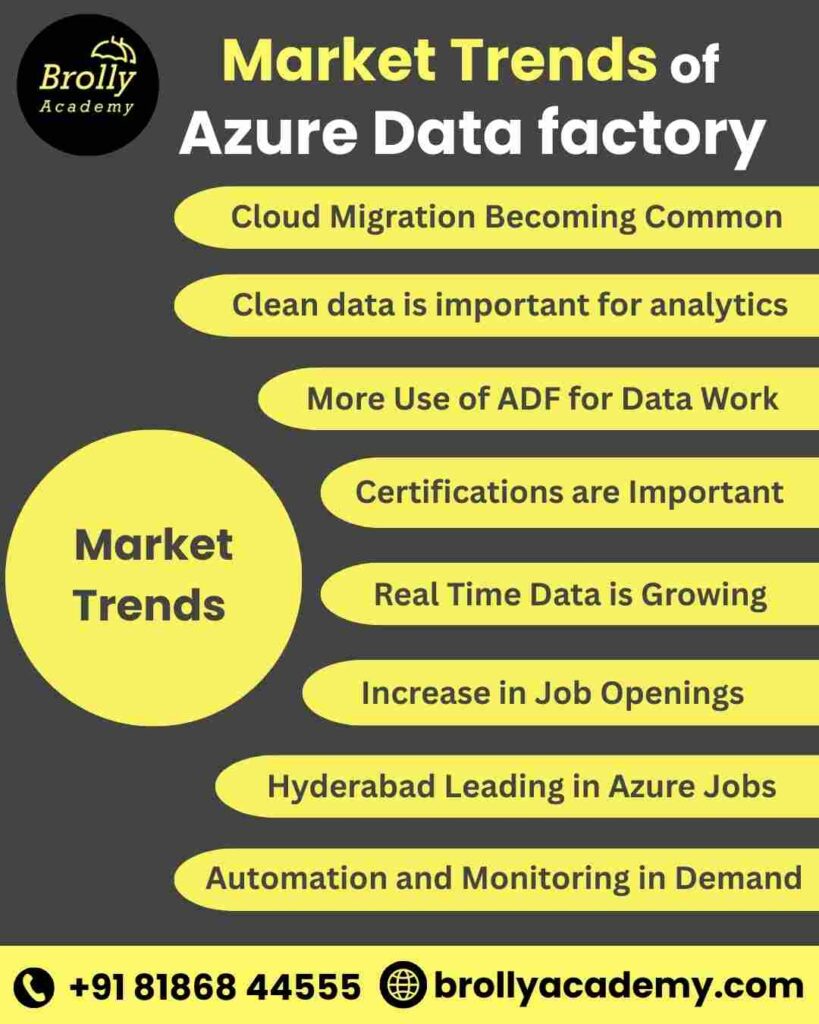
Market Trends of Azure Data Factory Course
- More Companies Using ADF for Data Work – Organizations now depend on Azure Data Factory pipelines and data flows to connect and manage data between systems.
- Cloud Migration Becoming Common – ADF migration skills are highly useful. Because many businesses are moving their data into Azure Data Lake and Synapse, by this ADF migration skills are highly useful.
- Real Time Data is Growing – As companies want quicker access to information, ADF is used for both real time and batch data processing
- Certifications are Important – Microsoft exams like DP-203 are helping professionals prove their ADF skills and stand out in job shortlisting.
- Clean data is important for analytics – ADF pipelines are preparing data for Power BI dashboards and Synapse reports. So, the demand for BI developers is increasing.
- Automation and Monitoring in Demand – Employers want people who can automate workflows, monitor pipelines, and fix issues quickly using ADF tools.
- Increase in Job Openings – Banking, healthcare, retail, and IT companies are actively hiring ADF developers, ETL engineers, and data analysts.
- Hyderabad Leading in Azure Jobs – MNCs and startups are investing in Azure, and ADF is now an important skill for data engineering careers in Hyderabad
Azure Data Factory Course in Hyderabad
FAQS
1. What is Azure Data Factory and why should I learn it?
Azure Data Factory is a cloud tool that helps you move, clean, and manage data using pipelines and workflows. Learning ADF gives you skills that are in high demand for cloud and data jobs.
2. Who can join the Azure Data Factory course in Hyderabad?
Freshers, IT professionals, data analysts, BI developers, and anyone interested in cloud or data careers can join this course.
3. Do I need coding knowledge to learn Azure Data Factory?
No, ADF provides drag and drop options for creating pipelines and data flows, so even beginners without coding experience can learn it easily.
4. What are the prerequisites for the ADF course?
Basic computer skills, some knowledge of SQL or databases, and an interest in data or cloud concepts are helpful but not mandatory.
5. What job roles can I apply for after learning ADF?
You can apply for roles like Azure Data Engineer, Azure ETL Developer, ADF Developer, BI Developer, Data Analyst, or Data Migration Specialist.
6. What is the salary for Azure Data Factory jobs in Hyderabad?
Entry level jobs start from ₹4 to 6 LPA, mid level roles pay around ₹10 to 15 LPA, and experienced professionals can earn ₹20+ LPA depending on skills and company.
7. How is Azure Data Factory used in real projects?
ADF is used to build pipelines, move data into Azure Data Lake or Synapse, automate workflows with triggers, and prepare clean data for reporting in Power BI.
8. Does the course cover real time projects?
Yes, you will work on projects like building ETL pipelines, connecting ADF with Synapse, migrating data to Azure Data Lake, and preparing dashboards with Power BI.
9. Will I get a certificate after completing the ADF course?
Yes, Brolly Academy provides a course completion certificate, and we also guide you for Microsoft certifications like DP-203.
10. Which Microsoft certifications are linked to ADF?
Certifications like DP-203 (Data Engineer Associate), AZ-900 (Fundamentals), DP-300 (Database Administrator), PL-300 (Power BI Analyst), and AZ-305 (Solutions Architect) include ADF concepts.
11. Is Azure Data Factory in demand in Hyderabad?
Yes, Hyderabad is a hub for IT and cloud jobs. MNCs and startups are hiring professionals with ADF skills for data engineering and integration projects.
12. Can freshers get jobs after learning Azure Data Factory?
Yes, freshers can apply for roles like Data Analyst, Junior ETL Developer, or ADF Developer if they complete projects and certifications.
13. How does ADF connect with other Azure services?
ADF pipelines can connect with Azure Data Lake, Synapse, Databricks, SQL Database, Event Hub, and Power BI for complete data solutions.
14. What is the difference between Azure Data Factory and Azure Data Engineer?
ADF is a service within Azure, while Data Engineer is a job role that uses ADF along with Synapse, Databricks, and SQL for end-to-end data solutions.
15. How long does it take to learn Azure Data Factory?
It usually takes 8 to 10 weeks of training with regular practice to understand ADF pipelines, triggers, monitoring, and integrations.
16. Do you provide placement support for ADF training?
Yes, we offer resume building, mock interviews, job referrals, and placement assistance to help you get placed in Hyderabad and other locations.
17. What is the role of pipelines in Azure Data Factory?
Pipelines are a set of steps that help move and transform data from one place to another in ADF.
18. What are mapping data flows in ADF?
Mapping data flows let you clean, join, filter, and prepare raw data into a ready format without writing heavy code.
19. Can ADF handle real time data?
Yes, ADF supports both batch and real time data processing using triggers and integration runtimes.
20. What industries are using Azure Data Factory in Hyderabad?
Industries like banking, healthcare, retail, IT services, and e-commerce are widely using ADF for data migration and analytics.
21. What tools are covered in the ADF course?
You will learn ADF tools like pipelines, triggers, linked services, datasets, mapping data flows, copy activity, lookup activity, and monitoring dashboards.
22. Will I get help in preparing for Microsoft exams?
Yes, we provide exam oriented training, practice questions, and tips for DP-203 and other certifications that include ADF.
23. How is Azure Data Factory different from SSIS?
While SSIS is server based, ADF is cloud based and supports big data with easy integration to Azure Synapse and Data Lake.
24. Can I take ADF training online as well as offline?
Yes, Brolly Academy provides online, offline, and hybrid training options
25. Why choose Brolly Academy for Azure Data Factory training in Hyderabad?
We provide industry expert trainers, real projects, placement support, classes in English & Telugu, and lifetime access to learning resources.
Other Relevant Courses






Got more questions?
Talk to Our Team Directly
Contact us and our academic councellor will get in touch with you shortly.
