
Apache Spark Training in Hyderabad
With
Certification & 100% Placement Assistance
Classroom Course | Online Course | Real-Time Projects | 30 Days Duration | Flexible EMI | Free Demo Class
Looking for the best Apache Spark Training in Hyderabad? Our certification program covers Spark Core, SQL, Streaming, PySpark, and Scala, with practical training on Databricks and Hadoop ecosystems. You’ll work on real-time big-data projects, learn to build and optimise distributed data pipelines, and gain the skills needed for data engineering and analytics roles. With expert mentors, flexible online/offline batches, and 100% placement assistance, we help you fast-track your career as a certified Apache Spark developer in just 30 days.
Table of Contents
ToggleApache Spark Course in Hyderabad
Next Batch Details
| Trainer Name | Mr Venkatesh (Certified Trainer) |
| Trainer Experience | 12+ Years of Industry & Teaching Experience |
| Next Batch Date | 15th December 2025 |
| Training Modes: | Online and Offline Training (Instructor-Led) |
| Course Duration: | 30 Days (Offline & Online) |
| Call us at: | +91 81868 44555 |
| Email Us at: | brollyacademy@gmail.com |
| Demo Class Details: | ENROLL FOR FREE DEMO CLASS |
Why Brolly Academy is the Best Apache Spark Training Institute in Hyderabad
10+
Years of Expertise in Big Data & Apache Spark Training
300+
Reviews Google ratings from students & working professionals
4.8
Ratings Consistently rated among Hyderabad’s top Spark training institutes
4,000+
Students Successfully Trained in Spark, PySpark & Data Engineering programs
30 Days
Duration
Modes
Multiple Modes Online, Offline & Hybrid learning options
Fee Range
Affordable Fees Flexible EMI plans & Free Demo Sessions available
15+
Projects Completed Hands-on projects using PySpark, Scala & Databricks
Why Choose Brolly Academy for Apache Spark Training in Hyderabad?
- Industry-ready Apache Spark curriculum designed for real-time data processing and analytics
- Expert trainer Mr Venkatesh with 12+ years of Big Data & Spark experience
- Hands-on projects on Spark Core, SQL, Streaming, PySpark, and Databricks
- Available in online & offline instructor-led training modes
- One-to-one mentorship with personalised career guidance
- Affordable fees with flexible EMI options for all learners
- Recognised as one of the best Apache Spark certifications in Hyderabad
- 2025-ready updated course content covering the latest Spark versions
- Lifetime access to recordings and learning materials
- Free 3-day demo classes before enrollment
- Resume building, LinkedIn optimisation, and mock interviews included
- Apache Spark course with 100% placement assistance
- Community learning via WhatsApp & Discord support groups
- Real-time capstone projects on Hadoop & Spark ecosystems
- Flexible training schedules — weekday & weekend batches
- Trusted by 4,000+ students trained in Big Data & Spark technologies
Apache Spark Course Curriculum in Hyderabad
Apache Spark Course Syllabus
- Introduction To Spark and Hadoop Platform
- Overview of Apache Hadoop
- Overview of Apache Spark
- Data, Locality, Ingestion and Storage
- Analysis and Exploration
- Other Ecosystem Tools
- Functional Programing Vs Object Orient Programing
- Scalable Language
- Overview of Scala
- Getting Started With Scala
- Scala Background, Scala Vs Java and Basics
- Running the Program with Scala Compiler
- Explore the Type Lattice and Use Type Inference
- Define Methods and Pattern Matching
- Ubuntu 14.04 LTS Installation VMware Player
- Installing Hadoop
- Apache Spark, JDK-8, Scala and SBT Installation
- Why we need HDFS
- Apache Hadoop Cluster Components
- HDFS Architecture
- Failures of HDFS 1.0
- Reading and Writing Data in HDFS
Fault Tolerance
- Configuring Apache Spark
- Scala Setup on Windows and UNIX
- Java Setup
- SCALA Editor
- Interprepter
- Compiler
- Benefits of Scala
- Language Offerings
- Type Inferencing
- Variables, Functions and Loops
- Control Structures
- Vals, Arrays, Lists, Tuples, Sets, Maps
- Traits and Mixins
- Classes and Objects
- First class Functions
- Clousers, Inheritance, Sub classes, Case Classes
- Modules, Pattern Matching, Exception Handling, FILE Operations
- Batch Versus Real-time Data Processing
- Introduction to Spark, Spark Versus Hadoop
- The Architecture of Spark
- Coding Spark Jobs in Scala
- Exploring the Spark Shell to Creating Spark Context
- RDD Programming
- Operations on RDD
- Transformations and Actions
- Loading Data and Saving Data
- Key Value Pair RDD
- Spark Streaming
- MLlib
- GraphX
- Spark SQL
- What is Apache Spark?
- Starting the Spark Shell
- Getting Started with Datasets and Data Frames
- Data Frame Operations
- Apache Spark Overview and Architecture
- RDD Overview
- RDD Data Sources
- Creating and Saving RDDs
- RDD Operations
- Transformations and Actions
- Converting Between RDDs and Data Frames
- Key-Value Pair RDDs
- Map-Reduce Operations
- Overview About Spark Documentation
- Initializing Spark Job
- Create Resilient Distributed Data Sets
- Previewing Data from RDD
- Transformations Overview
- Level Transformations Using Map and Flat Map
- Filtering the Data
- Inner Join and Outer Join
- Writing a Spark Application
- Building and Running an Application
- Application Deployment Mode
- The Spark Application Web UI
- Configuring Application Properties
- RDD Partitions
- Stages and Tasks
- Job Execution Planning
- Data Frame and Dataset Persistence
- Persistence Storage Levels
- Viewing Persisted RDDs
- Difference Between RDD, Data Frame and Dataset
- Common Apache Spark
- Different Interfaces to Run Hive Queries
- Create Hive Tables and Load Data in Text File Format & ORC File Format
- Using Spark-Shell to Run Hive Queries or Commands
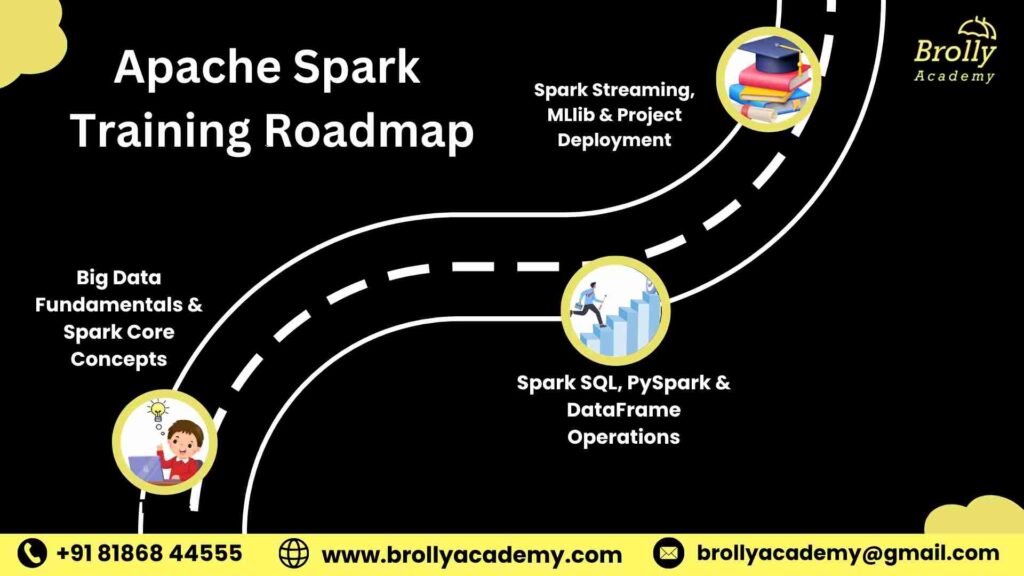
Apache Spark Training Roadmap – Beginner to Advanced
Apache Spark class Roadmap
Our Apache Spark Training in Hyderabad is structured into 3 progressive stages spread across 30 days. Each stage helps you move from understanding Spark fundamentals to mastering real-time data processing, PySpark scripting, and Databricks integration.
You’ll work on practical assignments and live projects that simulate real-world data engineering tasks, ensuring you don’t just learn Spark, but gain hands-on experience to become job-ready.
01
Week 1: Big Data Fundamentals & Spark Core Concepts
- Understand the Big Data ecosystem and Spark’s role in modern data engineering.
- Learn Hadoop vs Spark, Spark architecture, and cluster deployment.
- Explore RDDs (Resilient Distributed Datasets), transformations, and actions.
- Work with Spark Context, data partitioning, and fault tolerance.
- Perform hands-on practice on local and cluster environments.
02
Week 2: Spark SQL, PySpark & DataFrame Operations
- Dive into Spark SQL for querying structured data efficiently.
- Learn PySpark programming and DataFrame APIs for data analysis.
- Work with Hive integration, JDBC connections, and ETL pipeline building.
- Understand Catalyst optimiser, Tungsten engine, and performance tuning.
- Implement mini-projects involving SQL operations and data transformations.
03
Week 3–4: Spark Streaming, MLlib & Project Deployment
- Learn Spark Streaming and Structured Streaming for real-time data pipelines.
- Integrate Kafka, Flume, and HDFS for continuous data processing.
- Build and deploy Machine Learning models using Spark MLlib.
- Explore Databricks notebooks and Delta Lake for scalable analytics.
- End-to-end capstone project with deployment on cloud (AWS/Azure/GCP).
- Get complete placement preparation with resume sessions, mock interviews, and recruiter referrals.
What is Apache Spark?
- Apache Spark is a unified big data engine system.
- It executes large-scale data jobs in-memory fast.
- Designed for real-time and batch data analytics.
- Processes massive datasets using cluster systems.
- Built on Scala with APIs for Python and Java.
- Uses RDDs for fault-tolerant data distribution.
- Spark SQL helps run queries on large datasets.
- MLlib adds scalable machine learning models.
- GraphX is used for graph-based data computing.
- Integrates well with Hadoop, Hive, and Kafka.
- Ideal for ETL, AI, and big data engineering tasks.
- Open-source under the Apache Software Foundation.
Where is Apache Spark Used?
Industry | How It’s Used | Example |
Information Technology | For processing massive datasets, building ETL pipelines, and real-time analytics. | Data ingestion & transformation in Infosys and TCS projects. |
Finance & Banking | Used for fraud detection, risk modelling, and transaction analytics with real-time streaming data. | ICICI Bank uses Spark for transaction risk scoring. |
E-Commerce & Retail | Powers recommendation engines, customer segmentation, and clickstream analysis. | Amazon uses Spark for product recommendations. |
Telecommunications | Analyses call records and network performance for predictive maintenance. | Airtel applies Spark for customer churn prediction. |
Healthcare | Processes medical records, imaging data, and genomic analysis at scale. | Philips Healthcare leverages Spark for medical data pipelines. |
Transportation & Logistics | Optimises routing, fuel efficiency, and real-time tracking of fleet data. | Uber uses Spark for trip optimisation and analytics. |
Media & Entertainment | Used for user behaviour analytics, ad targeting, and content personalisation. | Netflix – Spark to recommend shows |
Education & Research | Supports large-scale data analysis for research and AI model training. | Stanford University uses Spark for big data research. |

Benefits of the Apache Spark Course in Hyderabad
Benefits of the Course
At Brolly Academy, we provide Apache Spark Training in Hyderabad through both online and offline classroom modes. You can choose a schedule that suits your availability while learning directly from expert trainers. The program includes hands-on projects, real-world data processing tasks, and complete placement support to help you become a certified Spark professional.
1. Learn from Certified Trainers
Step-by-step teaching by industry professionals with years of Big Data and Spark expertise.
2. Master Spark Components
Get trained in Spark Core, Spark SQL, Streaming, PySpark, and MLlib with real-time practice.
3. Work on Real Projects
Gain practical experience with end-to-end data pipelines using Databricks and Hadoop.
4. Get Job Assistance
Receive full support for resume building, interview prep, and placement referrals to top firms.
5. Earn a Certification
Obtain a recognised Apache Spark Certification, validating your expertise in data processing.
6. Build Data Engineering Skills
Learn how to design, optimise, and manage large-scale data processing workflows, including Data Science.
7. Understand Distributed Computing
Master RDDs, partitions, fault tolerance, and cluster management for scalable analytics.
8. Learn PySpark & Scala
Develop Spark applications using both Python and Scala, essential for modern data roles.
9. Hands-on with Spark SQL
Query structured and semi-structured data using Spark SQL and DataFrame APIs.
10. Handle Big Data Efficiently
Learn to process terabytes of data from multiple sources in real time.
11. Industry-Relevant Projects
Build practical projects aligned with data engineering and analytics job requirements.
12. Integration with Cloud & Hadoop
Work with AWS, Azure, and Hadoop for cloud-based data analytics and storage.
13. Flexible Learning Options
Choose between weekday, weekend, or fast-track batches with online and offline options.
14. Affordable Course Fee
Get high-quality Spark training in Hyderabad at a reasonable cost with EMI plans.
15. Join a Data Community
Network with data engineers, analysts, and mentors for continuous learning and support.
16. Future-Proof Career
Spark skills are in high demand, and your expertise will stay relevant for years to come, especially with Machine Learning with Python expertise.
Thinking of an Apache Spark Course in Hyderabad?
- Traditional Training
- You sit through theory sessions with limited practice.
- Uses outdated slides and older Spark materials.
- Trainers have only basic or general technical knowledge.
- Occasional lab work, mostly theoretical learning.
- No technical or placement support after course completion.
- Involves small exercises with no real-world impact.
- Limited or no placement assistance provided.
- One-size-fits-all teaching method for every learner.
- Brolly Academy Training
- You start working on real-time Apache Spark projects from day one.
- Covers the latest Spark versions, PySpark, and Databricks integration.
- Certified trainer Mr Venkatesh with 12+ years of Big Data experience.
- Daily practical training with Spark Core, SQL, and Streaming modules.
- Continuous placement guidance until successful job placement.
- Real-world big data projects added to your professional portfolio.
- Includes resume preparation, LinkedIn optimisation, and mock interviews.
- Customised mentorship and training based on your career goals.
Best Apache Spark Training Institute in Hyderabad
Meet Your Apache Spark Trainer
At Brolly Academy, you will learn from industry-certified trainers who have worked on real-time Big Data and Spark projects and trained hundreds of professionals and students in Hyderabad.
INSTRUCTOR
Mr. Venkatesh
Big Data & Apache Spark Specialist
Experience: 12+ years in Big Data, Apache Spark & Data Engineering
About the tutor:
Students Trained: 4,000+ in Hyderabad
Expertise: Spark Core, Spark SQL, Spark Streaming, PySpark, Databricks, Hadoop, and MLlib
Projects: Implemented end-to-end data processing pipelines using Spark on AWS and Azure, optimised ETL workflows, and developed real-time streaming applications for enterprise clients.
Teaching Style: Focuses on practical, hands-on learning with real-time datasets and projects, simplifying distributed computing concepts for all learners.

Skills You’ll Gain from Apache Spark Training in Hyderabad
Skills Developed after the course
- Build and manage distributed data pipelines using Apache Spark.
- Master Spark Core, Spark SQL, and Spark Streaming for data processing.
- Write Spark applications using PySpark and Scala APIs.
- Perform ETL operations on structured and unstructured datasets.
- Work with RDDs, DataFrames, and Datasets efficiently.
- Integrate Spark with Hadoop, Hive, Kafka, and HDFS for real-time analytics.
- Implement machine learning workflows using Spark MLlib.
- Optimise job performance using partitioning, caching, and tuning.
- Deploy Spark applications on Databricks, AWS EMR, and Azure HDInsight.
- Handle batch and stream data processing in one unified framework.
- Gain expertise in data engineering workflows and automation.
- Understand Spark’s architecture, fault tolerance, and DAG execution.
- Analyze big datasets for business intelligence and decision making.
- Learn debugging, monitoring, and log analysis for Spark jobs.
- Develop end-to-end real-time big data projects ready for deployment.
Apache Spark Capstone Projects in Hyderabad Training
Apache Spark Capstone Projects Covered
Our Apache Spark Training in Hyderabad is designed around real-time, industry-level projects that help you apply Spark concepts to real-world data problems. Whether you aim to become a Data Engineer, Big Data Developer, or Spark Analyst, these projects will give you the hands-on experience required to handle large-scale datasets and distributed processing environments confidently.
1. Real-Time Data Streaming with Kafka and Spark
Build a real-time streaming pipeline that processes continuous data streams using Apache Kafka and Spark Structured Streaming, commonly used in finance, IoT, and telecom industries.
2. ETL Pipeline with Spark and Hadoop
Design and deploy an end-to-end ETL workflow for data ingestion, transformation, and loading using Spark Core and Spark SQL integrated with HDFS and Hive.
3. Customer Behaviour Analytics using PySpark
Analyse massive datasets from e-commerce or retail sources to uncover customer trends, churn patterns, and segmentation insights using PySpark DataFrames.
4. Predictive Maintenance using Spark MLlib
Use Spark MLlib to build and train predictive models that forecast equipment failure based on sensor data, a common use case in manufacturing and logistics.
5. Log Data Analysis on Databricks
Implement a scalable log analytics system using Spark on Databricks, capable of handling millions of log entries to detect anomalies and monitor performance.
Tools Covered in Apache Spark Training in Hyderabad
Tools Covered










Apache Spark Course Fee & Offerings in Hyderabad
Apache Spark Training Fee & Offerings
Video Recording
Rs 15000 9999
- Lifetime access to recorded sessions
- Covers all Apache Spark modules (Core, SQL, Streaming, PySpark, MLlib)
- 60+ recorded classes
- 1 Capstone project included
- Resume and interview preparation support
- 100% placement assistance
- Access to the WhatsApp support group
Class Room Training
Rs 35000 29999
- 30-day structured classroom training (offline + lab sessions)
- Expert Apache Spark trainer (Mr Venkatesh) with 12+ years of experience
- Real-time industry projects (ETL pipelines, Streaming, Databricks)
- One-on-one mentorship & practical lab guidance
- Monthly mock interviews and project reviews
- Resume building & LinkedIn optimisation sessions
- Soft skills and aptitude development training
- Dedicated placement officer
- Commute support (offline batches)
- WhatsApp support + group access
Online Course
Rs 30000 24999
- Live interactive online classes with flexible timings
- 30-day program with daily recorded backup sessions
- Real-time projects on PySpark, SQL, and Streaming
- Weekly mock interviews & assessment sessions
- Dedicated doubt-clearing classes
- 50+ sample interview questions & Spark assignments
- Lifetime access to session recordings
- WhatsApp group and trainer support
Placement Program for Apache Spark Training in Hyderabad
Placement Program
At Brolly Academy, our Apache Spark course in Hyderabad includes a comprehensive 100% placement assistance program designed to help students not only master Spark but also secure jobs in top data engineering, analytics, and IT companies across Hyderabad and India.

Resume Building

Placement Training

Interview Questions

Realtime Live Projects

Get Offer Letter
Scheduling Interviews

Mock Interviews

Personality Development
- Resume Building: Craft professional, ATS-friendly resumes tailored for Apache Spark, Big Data, and Data Engineering job roles.
- Placement Training: Learn how to apply for jobs, prepare for technical and HR rounds, and understand industry hiring trends.
- Interview Questions Prep: Get access to top Apache Spark and PySpark interview questions commonly asked by MNCs.
- Internships Under Experts: Gain hands-on internship experience working on real Spark projects under industry mentors.
- Real-Time Projects: Build and showcase end-to-end data pipelines and streaming applications using Spark, Hadoop, and Databricks.
- Aptitude Preparation: Improve your logical reasoning, analytical skills, and technical problem-solving through guided sessions.
- Personality Development: Enhance communication, confidence, and interview etiquette through professional development workshops.
- Mock Interviews: Practice with technical and HR mock sessions focused on Spark-related questions to gain confidence.
- Scheduling Interviews: We connect you with hiring partners and arrange interviews with top recruiters in Hyderabad.
- Get Offer Letter: Receive placement offers from leading IT companies and data analytics firms across India.
What Our Students Say About Digital Marketing Training in Hyderabad
Testimonials
Apache Spark Student Community in Hyderabad
Student Community
At Brolly Academy, learning Apache Spark goes beyond classroom sessions. By joining our Spark Training in Hyderabad, you also become part of a vibrant student community where you can collaborate, share ideas, and grow with peers and mentors working in the Big Data and Data Engineering industry.
Learning & Collaboration
Work together with fellow learners on Spark-based data projects, share code snippets, and solve real-time challenges as a team.
Access to Resources and Tools
Get lifetime access to Spark materials, datasets, case studies, and project recordings to keep learning at your own pace.
Networking Opportunities
Build strong professional connections by engaging with data engineers, trainers, and recruiters from top IT companies in Hyderabad.
Mentorship from Industries Professional
Gain guidance from Big Data experts who mentor you on real-world project strategies, career planning, and interview success.
Job Support and Career Development
Stay informed about job openings, internship leads, and placement drives, and get continued support from our dedicated placement cell.
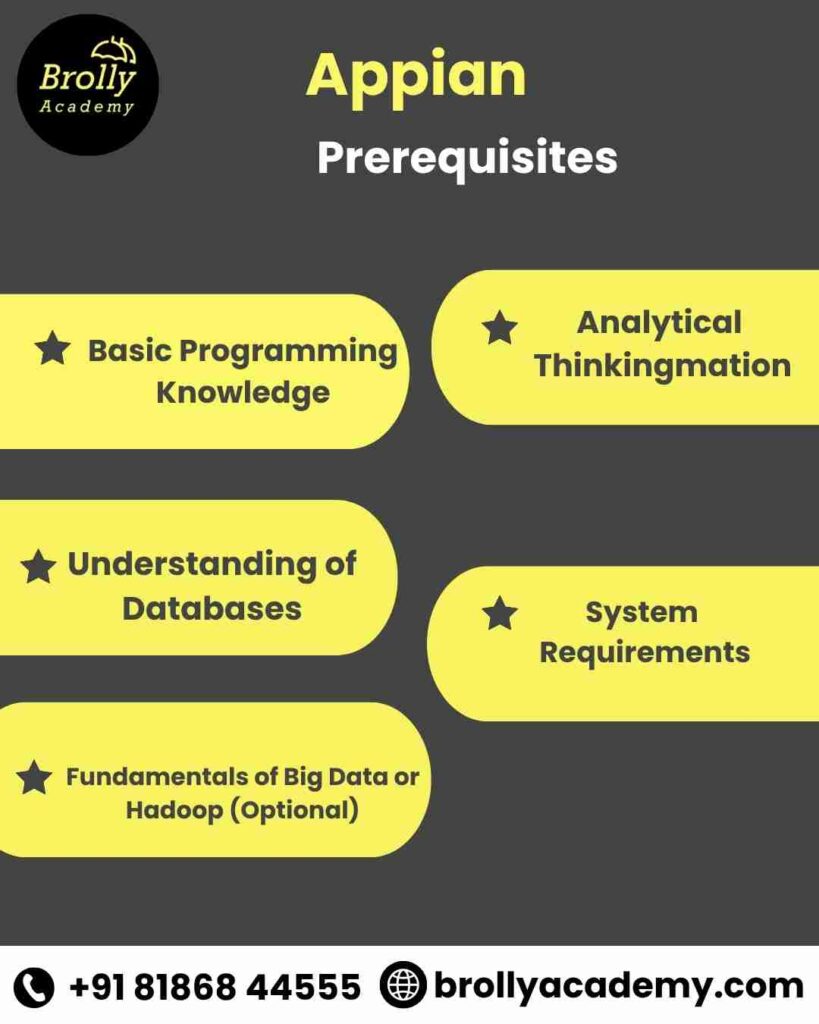
Pre-requisites for Apache Spark Training in Hyderabad
Pre-requisites
Before enrolling in the Apache Spark Course at Brolly Academy, having a few foundational skills will help you grasp concepts faster and make the most of the hands-on sessions. However, even beginners can join — our trainer ensures every topic starts from the basics.
- Basic Programming Knowledge: Familiarity with any programming language, such as Python, Java, or Scala, is recommended.
- Understanding of Databases: Knowledge of SQL queries and how data is stored, retrieved, and processed will be helpful.
- Fundamentals of Big Data or Hadoop (Optional): Basic awareness of HDFS, MapReduce, or Big Data concepts gives you a head start, but is not mandatory.
- Analytical Thinking: Comfort with data analysis, logic building, and problem-solving will enhance your learning experience.
- System Requirements: A computer with at least 8GB RAM, stable internet, and the ability to install software like Spark, Hadoop, or Databricks tools for hands-on practice.
Who Should Join Apache Spark Training in Hyderabad

- Students & Fresh Graduates: Ideal for graduates from Computer Science, IT, Electronics, or related fields who want to start their career in Big Data and Analytics.
- Software Developers: Professionals who want to upskill from traditional programming to big data processing and distributed systems using Spark.
- Data Analysts & BI Professionals: Analysts looking to analyse large datasets faster and move into advanced analytics or data engineering roles.
- Hadoop Developers: Those already familiar with Hadoop or MapReduce who want to transition to faster, in-memory data processing with Spark.
- Data Engineers & ETL Developers: Professionals working on data pipelines, ETL workflows, or data integration who want to improve performance and scalability.
- Machine Learning Engineers: ML professionals aiming to run large-scale model training using Spark MLlib and integrate distributed computation.
- IT Professionals Seeking a Career Change: Anyone from testing, support, or admin backgrounds who wants to move into high-demand Big Data and Cloud Analytics roles.
Career Opportunities After Apache Spark Training in Hyderabad
Career Opportunities

- Apache Spark Developer: Build and manage Spark-based applications for large-scale data processing and analytics.
- Big Data Engineer: Design and optimise ETL workflows and streaming data pipelines using Spark, Hadoop, and Kafka.
- Data Engineer: Handle structured and unstructured datasets for cloud-based data platforms like AWS, Azure, or GCP.
- PySpark Developer: Develop Spark applications using Python APIs (PySpark) for data transformation and machine learning tasks.
- Data Analyst / BI Engineer: Use Spark SQL and DataFrames to perform large-scale data analysis and visualisation.
- Machine Learning Engineer (MLlib): Build and deploy predictive models using Spark MLlib for scalable AI solutions.
- ETL Developer / Data Pipeline Engineer: Manage high-volume data integration between multiple enterprise sources and destinations.
Over 20,000+ job openings available for Apache Spark in Hyderabad for freshers
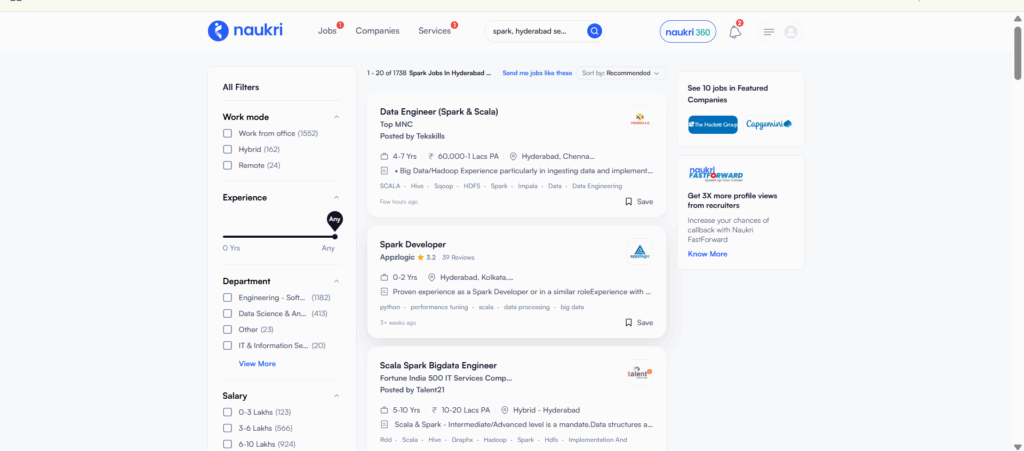
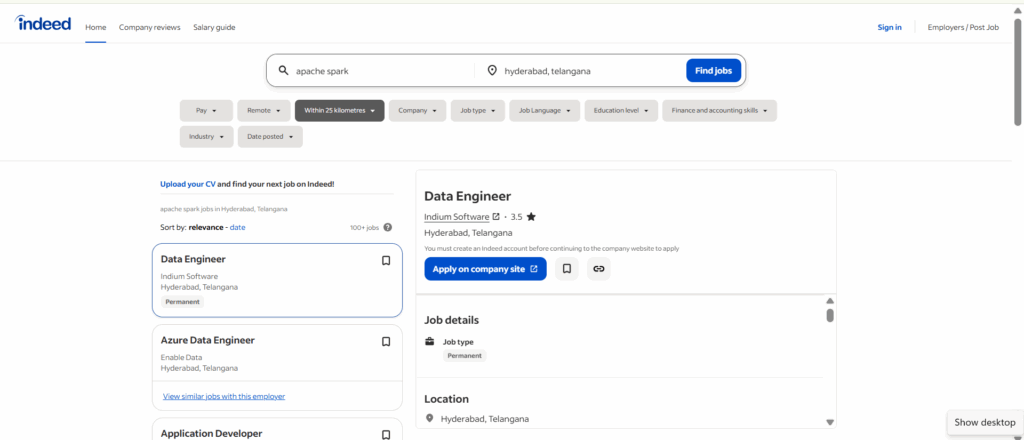
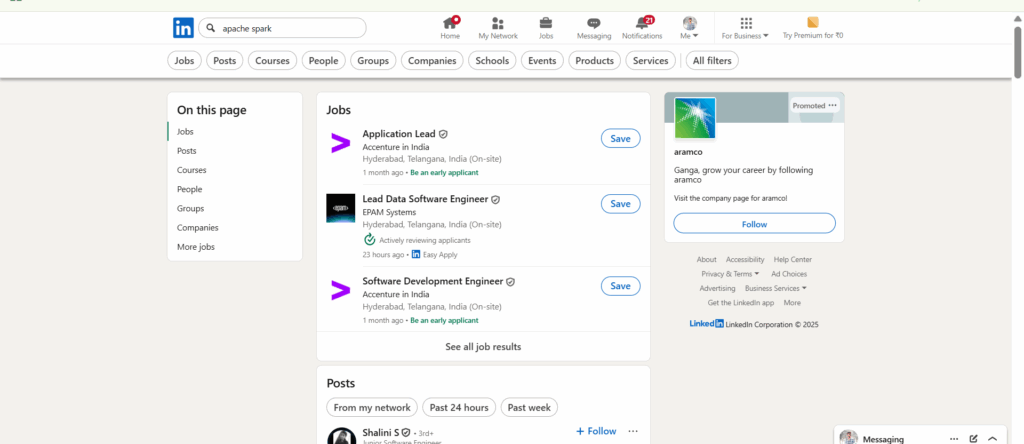
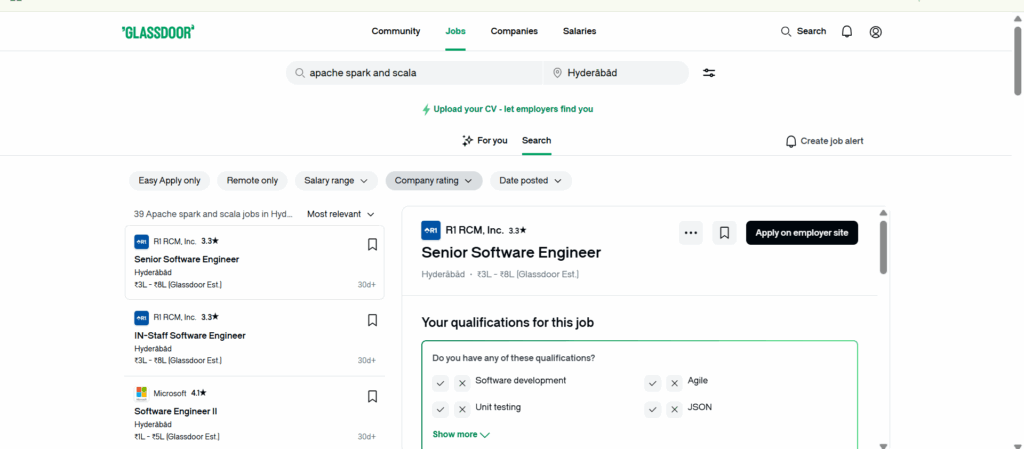
Apache Spark Developer Salary in Hyderabad – Freshers to Experienced
| Experience Level | Salary Range (Approx.) | Key Insights |
| Freshers (0–1 Year) | ₹4.2 LPA – ₹6 LPA | Entry-level roles like Junior Spark Developer or Big Data Associate focus on learning Spark Core, PySpark, and SQL. |
| Mid-Level (1–3 Years) | ₹6 LPA – ₹9 LPA | Professionals with hands-on experience in Spark SQL, Streaming, and Hadoop integration earn higher packages. |
| Experienced (3–5 Years) | ₹9 LPA – ₹13 LPA | Candidates skilled in Databricks, AWS EMR, and performance tuning are preferred by analytics firms and MNCs. |
| Senior Level (5–8 Years) | ₹13 LPA – ₹18 LPA | Roles include Senior Data Engineer or Spark Architect; experience in designing ETL workflows is highly valued. |
| Expert / Lead Level (8+ Years) | ₹18 LPA – ₹25 LPA+ | Spark professionals leading data architecture and real-time analytics teams in enterprises and product-based companies. |
Hiring Companies for Apache Spark Professionals in Hyderabad




Our Achievements in Apache Spark Training – Brolly Academy Hyderabad
Our Achievements
At Brolly Academy, we take pride in being one of the top training institutes in Hyderabad for Apache Spark and Big Data courses. Our consistent track record of excellence, placement success, and industry recognition makes us a trusted choice for thousands of learners.
50+ Batches Completed
12+ Years Trainer Experience
900+ Students Placed Across MNCs & Startups
4,000+ Students Trained In Spark, PySpark & Hadoop
90% Placement Success Consistent Placement Rate
Apache Spark Certifications You Will Receive in Hyderabad

Apache Spark Certifications You Will Receive
At Brolly Academy, every learner receives industry-recognised Apache Spark certifications that validate both theoretical knowledge and real-time project experience. These certificates help you stand out in the competitive job market and open doors to roles in Data Engineering, Big Data Analytics, and Cloud Data Platforms.
- Apache Spark Course Completion Certificate
- PySpark Developer Certification
- Databricks Integration & Streaming Certification
- Spark SQL and DataFrame Certification
- Spark MLlib (Machine Learning) Certification
- Big Data Project Completion Certificate
Market Trends for Apache Spark Professionals in Hyderabad
Market Trends
- Rising Demand: Organisations prefer Spark for real-time data streaming and faster analytics compared to traditional Hadoop.
- Cloud Integration: Major cloud providers like AWS, Azure, and GCP use Spark for scalable data pipelines and Databricks workflows.
- AI & Data Engineering Growth: Spark’s libraries — MLlib, SQL, and GraphX — power large-scale AI and machine learning pipelines.
- AI & Data Engineering Growth: Spark’s libraries — MLlib, SQL, and GraphX — power large-scale AI and machine learning pipelines.
- High Salaries: Skilled Spark developers earn 30–40% higher pay due to expertise in PySpark, Databricks, and cloud data systems.
- Future Outlook: The global Spark market is growing at 10%+ CAGR, and Hyderabad ranks among the top cities for Spark hiring in India.

Frequently Asked Questions – Apache Spark Training in Hyderabad
1. What is the best Apache Spark training in Hyderabad?
Brolly Academy offers the best Apache Spark Training in Hyderabad with real-time projects, 100% placement support, and certification. The program covers Spark Core, SQL, Streaming, and PySpark, making it ideal for both freshers and professionals.
2. What topics are covered in an Apache Spark course?
Our course includes Spark Architecture, RDDs, DataFrames, Spark SQL, PySpark, Spark Streaming, MLlib, and Databricks Integration, along with hands-on Big Data projects.
3. What are the prerequisites for learning Apache Spark?
Basic knowledge of Python, Java, or SQL is recommended, but not mandatory. We start from scratch, so even beginners can learn comfortably.
4. How much time will I need to finish the Digital Marketing course in Hyderabad?
Yes, Apache Spark is one of the top career choices in 2025. With the rise of data-driven companies, Spark developers are in high demand across India for Data Engineering and Analytics roles.
5. What is the salary of a Spark developer in India?
An entry-level Spark Developer earns around ₹4.5–6 LPA, while experienced professionals make ₹12–20 LPA, depending on skill set and project experience.
6. Which Spark certification is best for beginners?
The Databricks Certified Associate Developer for Apache Spark (Python/Scala) is the most recognised and beginner-friendly certification in 2025.
7. What is the cost of Spark certification in India?
Spark certification costs range from ₹9,000 to ₹22,000, depending on the provider. Brolly Academy includes certification with its training program at no additional fee.
8. What is the difference between Spark training online vs classroom in Hyderabad?
Our online batches offer flexibility and lifetime access to recordings, while offline training provides lab-based practical sessions and direct mentorship at our Hyderabad campus.
9. How long does it take to learn Apache Spark?
At Brolly Academy, it takes about 30 days to complete the course, including live projects, assignments, and interview preparation.
10. What companies hire Spark developers in Hyderabad?
Top recruiters include TCS, Accenture, Infosys, Wipro, Deloitte, Tech Mahindra, Capgemini, Cognizant, and HCLTech, along with several startups focusing on cloud and analytics.
11. What job roles can you get after completing Apache Spark training?
You can apply for roles such as Apache Spark Developer, Big Data Engineer, PySpark Developer, Data Engineer, or ETL Developer.
12. Is PySpark easier than Scala for Spark?
Yes, PySpark is easier for beginners since it uses Python syntax, but Scala offers better performance for advanced Spark projects. We train in both.
13. Can a fresher get a job after Apache Spark training?
Absolutely. Many of our students have secured jobs as Junior Data Engineers or Spark Developers right after completing the 30-day program.
14. What is Spark Streaming, and why is it important?
Spark Streaming allows real-time data processing from sources like Kafka, Flume, or IoT devices — crucial for modern analytics and business dashboards.
15. What is the scope of Apache Spark in data engineering?
Apache Spark is at the core of most data engineering pipelines, powering ETL processes, real-time analytics, and big data workflows in enterprise systems.
16. Does Apache Spark training include real-time project work?
Yes, our course includes real-time industry projects using Databricks, AWS, and Azure, so students gain hands-on practical experience.
17. How to choose the best Spark training institute in Hyderabad?
Look for institutes that offer certified trainers, real projects, placement support, and recognised certification — all of which Brolly Academy provides.
18. What certification exams are available for Apache Spark?
Popular options include:
- Databricks Certified Associate Developer
- Cloudera CCA175 Spark & Hadoop Developer
- HDP Spark Developer Certification
19. What is the difference between Spark SQL and Spark RDD?
Spark RDDs are low-level data structures used for complex transformations, while Spark SQL provides a high-level interface for querying structured data.
20. Can you get a free Spark certification?
Yes, some learning platforms and MOOCs offer free introductory Spark certifications, but for recognised credentials, paid exams like Databricks are preferred.
21. What are the admission criteria for Spark training in Hyderabad?
No strict criteria — anyone with basic computer knowledge or a background in IT, CS, or data-related fields can enrol.
22. What is Databricks certification for Apache Spark?
The Databricks certification validates your Spark programming skills and is highly valued by employers for both Python and Scala developers.
23. What is the role of machine learning in Spark (MLlib)?
MLlib is Spark’s machine learning library, enabling scalable model training, classification, and clustering directly on large datasets.
24. What industries demand Spark skills in India?
Spark professionals are in demand in finance, healthcare, e-commerce, telecom, and IT consulting industries.
25. What is Spark GraphX used for?
GraphX is Spark’s graph computation API used for social network analysis, recommendation systems, and graph-based data models.
26. What are the job growth trends for Spark developers in Hyderabad?
The Spark job market in Hyderabad has grown by over 40% in 2024–2025, driven by the increasing adoption of Databricks and cloud data platforms.
27. Are there placement guarantees for Spark training in Hyderabad?
Brolly Academy provides 100% placement assistance, including resume building, mock interviews, and direct recruiter connections until placement.
28. How does Spark compare to Hadoop MapReduce?
Spark is 100x faster than Hadoop MapReduce because it processes data in-memory, supports real-time streaming, and is much easier to code and maintain.
29. What is the difficulty level of learning Apache Spark?
With guided training and practical projects, Spark is beginner-friendly. Most students become comfortable within the first two weeks of training.
30. Is Spark certification worth it for a salary increase in India?
Yes. Certified Spark professionals earn 20–35% higher salaries, and certifications like Databricks greatly improve your hiring potential.
Other Relevant Courses






Got more questions?
Talk to Our Team Directly
Contact us and our academic councellor will get in touch with you shortly.
