

Overview Of Reinforcement Learning In AI
What is Reinforcement Learning In AI?
- Reinforcement Learning (RL) is a powerful branch of Artificial Intelligence where machines learn by interacting with an environment, making decisions, and improving through feedback.
- Instead of being given direct answers, an RL agent learns through trial and error, receiving rewards for correct actions and penalties for wrong ones.
- This approach enables AI systems to discover the best strategies for solving complex problems on their own.
- Reinforcement learning plays a major role in many advanced applications such as self-driving cars, robotics, gaming systems like AlphaGo, recommendation engines, autonomous machines, and smart control systems.
- By continuously learning from outcomes and adjusting actions, RL allows machines to adapt, optimize, and perform tasks that would otherwise require human decision-making.
Introduction to Reinforcement Learning
- Reinforcement Learning (RL) is a fascinating branch of Artificial Intelligence where machines learn to make decisions by interacting with an environment and receiving feedback through rewards or penalties.
- Unlike traditional supervised learning, where models learn from labeled data, RL enables systems to learn through experience—similar to how humans learn from trial and error.
- This makes reinforcement learning extremely important in AI, especially for solving complex, dynamic problems such as robotics, self-driving cars, gaming strategies, autonomous control systems, and real-time decision-making tasks.
- In this blog, we will explore what reinforcement learning is, how it works, the key components involved, different types of RL, real-world applications, its advantages and challenges, and the future possibilities it brings.
- This structured guide aims to give beginners a complete understanding of why reinforcement learning is one of the most powerful and rapidly evolving areas in artificial intelligence.
Comparison of Reinforcement Learning vs Supervised vs Unsupervised Learning
Aspect | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
Definition | Learns from labeled data with correct input–output pairs. | Learns from unlabeled data by finding patterns and structures. | Learns by interacting with an environment and receiving rewards or penalties. |
Learning Method | Mapping inputs to outputs using labeled examples. | Discovering hidden patterns in data without any labels. | Trial-and-error learning to maximize cumulative rewards. |
Data Requirement | Requires large labeled datasets. | Requires large amounts of raw, unlabeled data. | Does not require labeled data; needs an interactive environment. |
Goal | Predict accurate outputs for new data. | Group, cluster, or reduce dimensionality of data. | Find the best long-term strategy (policy) to choose actions. |
Feedback Type | Direct feedback (correct answer provided). | No explicit feedback; learns structure automatically. | Delayed feedback (rewards/penalties after actions). |
Examples of Algorithms | Linear Regression, SVM, Decision Trees, Neural Networks. | K-Means, PCA, Hierarchical Clustering, Autoencoders. | Q-Learning, SARSA, Deep Q-Networks (DQN), Policy Gradient methods. |
Best Used For | Classification, regression, prediction tasks. | Pattern detection, segmentation, anomaly detection. | Robotics, game playing, self-driving cars, autonomous systems. |
Environment Interaction | No interaction; learns from static datasets. | No interaction; analyses existing data. | Continuous interaction with the environment is required. |
Key Advantage | High accuracy with good labeled data. | Reveals hidden insights without labels. | Learns complex decision-making strategies autonomously. |
Historical context and development of reinforcement learning
- The history of Reinforcement Learning (RL) is deeply rooted in behavioral psychology, mathematics, and computer science.
- The concept first emerged from behavioral conditioning experiments, where researchers like Edward Thorndike and B.F. Skinner studied how animals learn through rewards and punishments.
- Their findings laid the foundation for the idea that actions followed by positive outcomes are more likely to be repeated—an idea that directly inspired modern reinforcement learning.
- The mathematical grounding of RL began in the mid-20th century with the development of dynamic programming, introduced by Richard Bellman.
- Bellman’s work on the Bellman Equation provided a formal method for solving decision-making problems and optimizing long-term rewards.
- This marked a major turning point, linking psychology’s reward-based learning with mathematical optimization.
- Reinforcement learning took a significant leap forward in the 1980s and 1990s, when researchers developed key algorithms such as Temporal Difference (TD) Learning, Q-Learning (by Christopher Watkins), and SARSA.
- These breakthroughs allowed machines to learn optimal actions without needing a model of the environment, making RL far more practical for real-world applications.
- The modern era of reinforcement learning began with the rise of deep learning.
- In 2013, DeepMind revolutionized the field by combining neural networks with RL, creating Deep Q-Networks (DQN) capable of achieving human-level performance on Atari games. Soon after, achievements like AlphaGo, AlphaZero, and robotic control systems showed the world that reinforcement learning could solve highly complex, high-dimensional problems once thought impossible.
- Today, reinforcement learning continues to evolve rapidly, powering advancements in robotics, autonomous driving, smart decision systems, healthcare automation, and financial modeling.
- Its history reflects a continuous blend of psychology, mathematics, and AI innovation, making RL one of the most transformative fields in modern artificial intelligence.
How Reinforcement Learning Works
Reinforcement Learning works by allowing an AI system to learn through interaction, feedback, and continuous improvement. Instead of being given the correct answers, the model discovers them on its own by trying different actions and evaluating the outcomes. This makes RL highly effective for complex, dynamic environments where decisions must be made step by step.
A. The Learning Process: Trial and Error
At its core, reinforcement learning is based on trial and error, similar to how humans and animals learn from experience. The agent takes an action, observes what happens, and learns whether the outcome was good or bad. If the action leads to a beneficial result, the agent receives a reward; if the outcome is unfavorable, it receives a penalty.
Over time, the agent tries different actions, learns from past mistakes, and adjusts its behavior to maximize long-term rewards. This continuous loop of action → feedback → learning enables the agent to gradually develop an optimal strategy or policy.
B. Role of the Agent, Environment, and Rewards
Reinforcement Learning revolves around three main elements:
1. Agent
- The decision-maker that takes actions in order to achieve a goal.
- It constantly updates its strategy based on past interactions.
2. Environment
- The external system or world in which the agent operates.
- It responds to the agent’s actions and provides feedback such as new states and rewards.
Examples: a game, a robot’s surroundings, or a traffic simulation.
3. Rewards
The feedback signal that tells the agent how good or bad an action was.
- Positive rewards encourage good behavior, while negative rewards discourage undesirable actions.
- Together, these components form the reinforcement learning loop, where the agent interacts with the environment repeatedly, gathers experiences, and improves performance over time.
C. The Concept of Exploration vs. Exploitation
One of the biggest challenges in reinforcement learning is balancing exploration and exploitation:
Exploration
- Trying new actions to discover better strategies, outcomes, or rewards.
- This helps the agent learn about unfamiliar states or alternative paths.
Exploitation
- Using the knowledge the agent already has to choose the best-known action.
- This helps maximize immediate rewards based on past experience.
- A successful reinforcement learning model must balance both.
- Too much exploration may waste time on unproductive actions, while too much exploitation may prevent the agent from discovering better solutions.
- Modern RL algorithms use strategies like ε-greedy, softmax, and UCB methods to manage this balance effectively.

Key Components of Reinforcement Learning
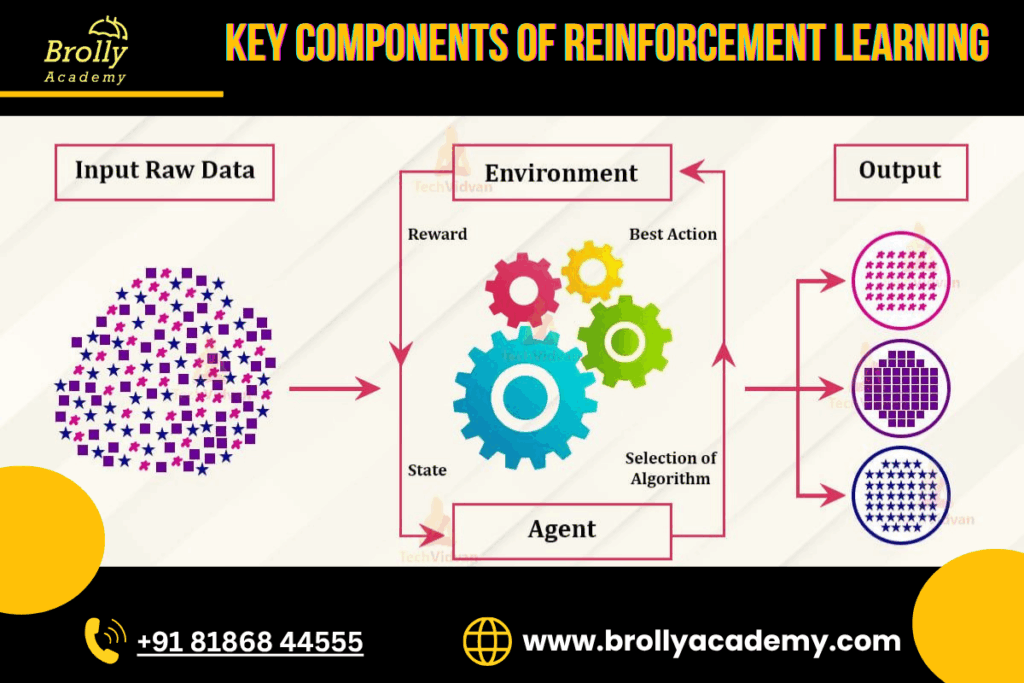
Reinforcement Learning is built on several fundamental components that work together to help an AI agent learn from experience. Each component plays a unique role in shaping how the agent interacts with its environment and improves over time. Understanding these elements is crucial to understanding how RL algorithms function. Below is a breakdown of all key components and their purposes.
A. Agent
What it is:
The agent is the learner or decision-maker in reinforcement learning. It observes the environment, takes actions, and learns from the outcomes.
Purpose:
To choose the best possible actions based on past experiences and maximize long-term rewards. The agent continuously updates its strategy (policy) as it interacts with the environment.
B. Environment
What it is:
The world in which the agent functions is known as the environment.. It can be a game, a robot’s surroundings, a simulation, or any system that reacts to the agent’s actions.
Purpose:
To provide the agent with feedback—new states and rewards—after every action. It defines the rules, constraints, and consequences of the agent’s behavior.
C. State
What it is:
A state represents the current situation or condition of the environment as perceived by the agent. Examples: position of a robot, score in a game, traffic signal status.
Purpose:
To give the agent all the information it needs to decide what action to take next. The better the state representation, the more effective the learning.
D. Action
What it is:
An action is a step or decision the agent takes in response to a state. Actions depend on the type of environment (e.g., moving left, accelerating, placing a bet, switching lanes).
Purpose:
To interact with the environment and influence future states and rewards. Actions directly determine the agent’s success or failure in achieving its goals.
E. Reward
What it is:
A reward is a numerical signal the agent receives after taking an action. It can be positive (success) or negative (penalty).
Purpose:
To guide the agent’s learning process. Rewards help the agent understand which actions are beneficial and should be repeated, and which actions lead to negative outcomes.
F. Policy
What it is:
A policy is the strategy the agent follows to decide which actions to take in different states. It can be simple (a table of rules) or complex (a neural network).
Purpose:
To map states to actions effectively. The goal of reinforcement learning is to discover an optimal policy that maximizes long-term rewards.
G. Value Function
What it is:
A value function estimates how good a particular state or action is, based on expected future rewards. It predicts long-term benefits rather than immediate reward.
Purpose:
To help the agent evaluate future outcomes and plan ahead. While rewards give immediate feedback, the value function helps the agent consider long-term consequences, enabling smarter decision-making.

Types of Reinforcement Learning
A. Model-based vs. Model-free
Model-based RL builds or uses a model of the environment (a predictive map of how states change after actions and what rewards result). The agent plans by simulating future sequences of actions in the learned model and choosing the best trajectory.
Pros: Generally more sample efficient (needs fewer real interactions), can plan long horizons, and can reuse learned models for different tasks.
Cons: Building an accurate model can be hard for complex or noisy environments; model errors can hurt performance.
Model-free RL skips building an explicit environment model and directly learns a policy or value function from experience (e.g., Q-learning, policy gradients).
Pros: Simpler to implement; often more robust when modeling is infeasible.
Cons: Usually less sample efficient and may require many interactions or simulations to learn good policies.
B. On-policy vs. Off-policy
On-policy methods learn the value of the policy that is currently being used to make decisions. The agent evaluates and improves the same policy that generates experience (example: SARSA).
Use case: Safer exploration when learning must follow a particular strategy.
Off-policy methods learn about an optimal policy independently of the agent’s current behavior. They can use data collected under different policies (example: Q-Learning, DQN).
Use case: Reuse of past experience, learning from demonstrations, and more efficient learning from diverse data sources.
C. Overview of algorithms used in reinforcement learning
Tabular methods: Q-learning, SARSA — for small, discrete state/action spaces (simple, interpretable).
Temporal Difference (TD) methods: Combine dynamic programming and Monte Carlo ideas (TD(0), TD(λ)).
Policy Gradient methods: Directly optimize a parameterized policy (REINFORCE, Actor-Critic). Good for continuous action spaces.
Actor-Critic methods: Two models — actor (policy) and critic (value) — that learn together (A2C, A3C, PPO).
Deep RL: Neural networks approximate policies and value functions (DQN, DDPG, PPO, SAC).
Imitation & Offline RL: Learn from demonstrations or fixed datasets without active interaction.
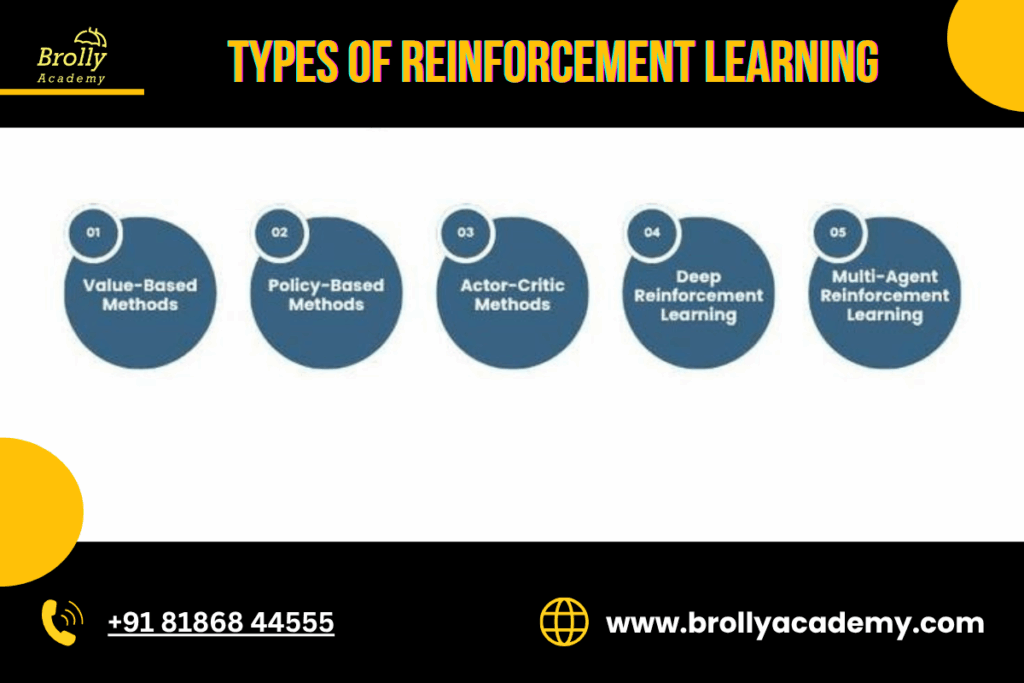
Deep Reinforcement Learning
A. Definition and significance
Deep Reinforcement Learning (Deep RL) combines RL algorithms with deep neural networks to handle high-dimensional inputs (images, sensor data) and complex function approximations. Deep RL enables agents to learn directly from raw inputs and to scale to real-world problems that traditional tabular methods cannot solve.
Why it matters: Deep RL unlocked breakthroughs in domains like game playing (Atari, Go), robotic control, and continuous control tasks, making RL practical for modern AI systems.
B. Integration of deep learning with reinforcement learning
Neural networks are used to approximate:
Value functions (e.g., DQN uses a neural network to estimate Q-values),
Policies (policy networks output continuous or discrete action probabilities),
State representations (CNNs for images, RNNs for partial observability).
Techniques to stabilize learning: experience replay, target networks, gradient clipping, entropy regularization, and normalization. These methods address instability introduced by combining off-policy updates and function approximation.
C. Notable architectures and frameworks
DQN (Deep Q-Network): First to show human-level performance on Atari games by using replay buffers and target networks.
Policy optimization methods: PPO (Proximal Policy Optimization) — stable and popular for robotics and continuous control.
Off-policy continuous control: DDPG, TD3, SAC — suited for continuous action spaces.
Alpha family (AlphaGo/AlphaZero): Combine Monte Carlo tree search (MCTS) with deep networks for board games.
Frameworks & libraries: TensorFlow, PyTorch, Stable Baselines3, RLlib — widely used for research and production.
Applications of Reinforcement Learning
A. Robotics
RL empowers robots to learn locomotion, grasping, and manipulation by trial and error in simulation and real world. Sim-to-real transfer and domain randomization are common strategies to bridge simulation and hardware.
B. Game Playing (e.g., AlphaGo)
RL has produced superhuman game-playing agents: DeepMind’s AlphaGo and AlphaZero used self-play and deep networks to master Go, Chess, and Shogi, showcasing RL’s ability to learn complex strategies.
C. Autonomous Vehicles
RL helps optimize driving policies, lane changes, and motion planning. It is commonly used in simulation to develop decision-making modules that must handle dynamic traffic and uncertain environments.
D. Healthcare
Applications include treatment planning, adaptive dosing, and personalized therapy policies where RL recommends sequences of interventions to optimize patient outcomes
E. Finance
RL is used in algorithmic trading, portfolio optimization, and risk management by learning policies that maximize long-term returns or minimize risk under market dynamics.
Advantages of Reinforcement Learning
A. Ability to learn from interaction
- RL agents learn policies through direct interaction, making them suitable for tasks where labeled examples are impractical or impossible.
B. Flexibility in various applications
- From discrete games to continuous control, RL can be tailored (model-based, model-free, hierarchical) to fit different problem structures and constraints.
C. Potential for high performance in complex tasks
- When provided enough experience and compute, RL agents can discover novel, high-performing strategies beyond human intuition (e.g., game strategies, robotic gaits).
Challenges in Reinforcement Learning
A. Sample efficiency
- Many RL algorithms require huge numbers of interactions (episodes) to learn—an issue for real-world systems where data collection is costly or slow.
B. Stability and convergence issues
- Combining function approximation (neural networks) with bootstrapping and off-policy updates can cause instability, divergence, or catastrophic forgetting.
C. Scalability and computational demands
- Training state-of-the-art RL agents often requires heavy compute (GPUs/TPUs), large memory for replay buffers, and extensive hyperparameter tuning.
D. Ethical considerations
- RL systems can discover harmful or biased behaviors if reward design is flawed. Safety, interpretability, fairness, and alignment with human values are critical concerns—especially for high-stakes applications.
Future of Reinforcement Learning
A. Emerging trends and research directions
Sample-efficient methods: Model-based RL, meta-learning, and more efficient off-policy methods.
Safe and interpretable RL: Constraining behavior, formal verification, and explainability.
Multi-agent RL: Coordination, competition, and emergent behaviors in multi-agent environments.
Offline RL & learning from demonstrations: Learning policies from fixed datasets and human demonstrations.
Hybrid systems: Combining symbolic reasoning, classical planning, and RL for better generalization.
B. Potential impact on various industries
- RL is poised to transform manufacturing (autonomous factories), transportation (fleet optimization), healthcare (personalized treatment), finance (adaptive trading), and consumer tech (adaptive recommendation systems).
C. Integration with other AI technologies
- Reinforcement learning will increasingly combine with large language models, causal inference, unsupervised representation learning, and computer vision to create more general, adaptable AI agents.
Conclusion
A. Recap of key points discussed
Reinforcement Learning enables agents to learn optimal behaviors by interacting with environments and maximizing cumulative rewards. It differs from supervised and unsupervised learning, includes core components like agent, state, action, reward, policy, and value function, and is split across types such as model-based/model-free and on-policy/off-policy.
B. The significance of reinforcement learning in the future of AI
RL has already delivered breakthroughs in games, robotics, and control, and its continued progress promises powerful, adaptive systems that address complex, sequential decision problems.
C. Encouragement for further exploration and learning in the field
For beginners: start with classic algorithms (Q-learning, SARSA), move to deep RL (DQN, PPO), and practice in simulation environments (OpenAI Gym, Unity ML-Agents). Read research papers, try open-source libraries, and experiment—RL rewards curiosity and iterative learning.
FAQs
1. What is Reinforcement Learning in AI?
Reinforcement Learning (RL) is a machine learning technique where an agent learns by interacting with an environment, taking actions, and receiving rewards or penalties to improve long-term performance.
2. How does reinforcement learning work in simple terms?
RL works through trial and error. The agent performs an action, observes the outcome, gets a reward, and gradually improves its decisions.
3. What makes reinforcement learning different from supervised learning?
In supervised learning, models learn from labeled data, while in RL, the agent learns from experience without explicit labels.
4. What are some common real-world applications of reinforcement learning?
RL is used in robotics, game AI, self-driving cars, finance, industrial automation, healthcare optimization, and recommendation systems.
5. What is a reward function in reinforcement learning?
The reward function defines how the agent is evaluated. It provides positive or negative feedback for actions taken in the environment.
6. What is a policy in reinforcement learning?
A policy determines the agent’s behavior by mapping states to actions. It can be deterministic or probabilistic.
7. What is Q-Learning in reinforcement learning?
Q-Learning is a model-free RL algorithm that learns the value of actions in different states using a Q-table or neural network.
8. What is Deep Reinforcement Learning (DRL)?
DRL combines reinforcement learning with deep neural networks, enabling agents to learn from high-dimensional data such as images or sensor inputs.
9. What is the role of neural networks in Deep RL?
Neural networks approximate complex value functions or policies, allowing RL agents to scale to environments with millions of states.
10. What is an episode in reinforcement learning?
An episode is a complete sequence of interactions from the initial state to a terminal state, such as finishing a game level or completing a task.
11. What is exploration in reinforcement learning?
Exploration involves taking new or random actions to discover better strategies instead of relying solely on known behaviors.
12. What is exploitation in reinforcement learning?
Exploitation means choosing the best-known action based on learned knowledge to maximize rewards.
13. What is the exploration vs. exploitation challenge?
RL must balance exploring new actions and exploiting known optimal actions to achieve long-term success.
14. What is the difference between model-based and model-free RL?
Model-based RL predicts future states and rewards using a learned model.
Model-free RL learns from experience without predicting environment dynamics.
15. What are on-policy and off-policy reinforcement learning methods?
On-policy methods learn from actions taken using the same policy (e.g., SARSA).
Off-policy methods learn about one policy while following another (e.g., Q-Learning).
16. What is an action-value function (Q-value)?
It represents the expected future reward from taking a specific action in a specific state under a certain policy.
17. What is the state-value function (V-value)?
It estimates the total future reward from a particular state when following a given policy.
18. What is the Markov property in reinforcement learning?
The Markov property states that future outcomes depend only on the current state and not on past states.
19. What is temporal difference (TD) learning?
TD learning updates value estimates using the difference between predicted and actual rewards, enabling learning without complete episodes.
20. What is policy gradient in reinforcement learning?
Policy gradient methods directly optimize the policy using gradient-based techniques and are effective for high-dimensional action spaces.
21. What are actor-critic methods?
Actor-critic combines policy-based (actor) and value-based (critic) methods to improve stability and performance in RL.
22. What is a reward shaping in reinforcement learning?
Reward shaping improves training efficiency by modifying the reward function to guide the agent more effectively.
23. What is multi-agent reinforcement learning?
Multi-agent RL involves multiple agents learning simultaneously in a shared environment, often competing or cooperating.
24. What is inverse reinforcement learning (IRL)?
IRL learns the reward function by observing expert behavior instead of manually defining reward signals.
25. What is offline (batch) reinforcement learning?
Offline RL learns from pre-collected datasets without interacting with the environment, making it safer for high-risk applications like healthcare.
26. What is hierarchical reinforcement learning (HRL)?
HRL breaks tasks into smaller sub-tasks, enabling efficient learning in complex environments with layered goals.
27. What are the biggest challenges in reinforcement learning?
Some major challenges include sample inefficiency, environment instability, high computational cost, and reward design complexity.
28. How long does it take to train a reinforcement learning model?
Training time depends on environment complexity, algorithm type, reward structure, and computational resources. Some tasks take minutes, others weeks.
29. What tools and frameworks are commonly used for reinforcement learning?
Popular RL frameworks include TensorFlow Agents (TF-Agents), PyTorch RL, OpenAI Gym, Stable Baselines3, RLlib, and DeepMind’s Acme.
30. What is the future of reinforcement learning?
The future of RL includes real-time robotics, autonomous decision-making systems, large-scale industrial automation, personalized healthcare, and integration with generative AI and agentic systems.