
25+ Data Science Projects with Source Code [Beginners to Advanced]
![25+ Data Science Projects with Source Code [Beginners to Advanced]](https://brollyacademy.com/wp-content/uploads/2025/07/Data-Science-Projects-with-Source-Code-1024x538.png)
Introduction
Data Science isn’t just theory, it’s practice. If you’re aiming to become a data scientist, there’s no better way to master the skill than by building real-world data science projects with source code. Whether you’re a beginner, a student preparing for your final-year project, or an experienced developer looking to upskill, this guide is crafted for you.
In this article, you’ll find:
- 50+ curated data science project ideas
- GitHub source code links
- Project overviews and tech stacks
- Category-wise breakdown (ML, NLP, Deep Learning, Tools, and Domains)
Before You Start: Prerequisites & Tools
✅ Skills You Should Know
- Python Programming
- Data Analysis (NumPy, Pandas)
- Data Visualization (Matplotlib, Seaborn)
- Machine Learning Basics
- Jupyter Notebook
🧰 Tools & Frameworks
Category | Tools |
Programming | Python, R |
IDE | Jupyter Notebook, VSCode |
Libraries | Scikit-learn, TensorFlow, Keras, PyTorch |
Datasets | Kaggle, UCI ML Repo, Google Dataset Search |
👉 Tip: Use virtual environments (like conda or venv) to manage dependencies per project.

Top Data Science Projects by Category
Machine Learning Project: House Price Prediction
Dataset
- Kaggle Ames Housing Dataset: Includes 79 variables covering lot size, year built, sale price, and more arXiv+12inria.github.io+12GitHub+12
Tools
- Python, Scikit‑learn, Pandas, NumPy, Matplotlib, Seaborn, XGBoost, Streamlit or FastAPI
Description
- Clean and preprocess data (handle missing values, outliers, categorical encoding)
- Perform exploratory data analysis (EDA) with correlation matrices and feature distributions
- Engineer features (polynomial, interaction terms, dummies) to improve model accuracy
- Train regression models (Linear Regression, Random Forest, XGBoost)
- Optimize with hyperparameter tuning (GridSearchCV/RandomizedSearchCV)
- Evaluate using RMSE, MAE, R² metrics
- Deploy as an interactive web app using Streamlit or a REST API via FastAPI
GitHub Source Code
- sinhasagar507/Ames‑house‑price‑prediction
- Complete ML pipeline and Streamlit app
- ~79 feature preprocessing → Regression → model deployment
- arXiv+13GitHub+13GitHub+13GitHub
- Complete ML pipeline and Streamlit app
- ugursaricam/house‑price‑prediction
- Implements multiple regression models with clean code structure
- GitHub+1GitHub+1
- Implements multiple regression models with clean code structure
- Shiva‑Prasad‑Naroju/Ames‑Housing‑ML‑project
- Modular pipeline with notebooks and source separation
- YouTube+11GitHub+11GitHub+11inria.github.io+8en.wikipedia.org+8GitHub+8
- Modular pipeline with notebooks and source separation
2. Machine Learning Project: Loan Default Prediction
Dataset
- Lending Club Loan Data (2007–2018): ~2.2 million loan records, including attributes like loan_amount, interest_rate, employment_length, loan_status, and more Kaggle+12GitHub+12LinkedIn+12
Tools
- Python, XGBoost, Scikit-learn, pandas, NumPy, Matplotlib, Seaborn, optionally Streamlit or FastAPI
Description
- Load and preprocess data: remove high-missing-value columns, encode categorical variables (home_ownership, verification_status), scale numeric features, address class imbalance via class weighting or resampling (SMOTE).
- Conduct Exploratory Data Analysis: visualize feature distributions, correlation heatmaps, default-rate scatter plots.
- Feature engineering: derive features like debt_to_income_ratio, loan_term_months, employment_years.
- Train classification models: baseline (Logistic Regression), tree-based (Random Forest, XGBoost).
- Optimize hyperparameters via GridSearchCV or Bayesian optimization.
- Evaluate model performance using accuracy, precision, recall, F1-score, ROC-AUC.
- (Optional) Deploy with Streamlit or FastAPI for interactive user interface or REST API access.
GitHub Source Code Examples
- Luissalazarsalinas/Loan-Default-Prediction
- End-to-end ML pipeline and Streamlit dashboard for loan default prediction using XGBoost and Random Forest GitHub+1Medium+1GitHub+2MDPI+2GitHub+2GitHubGitHub+2GitHub+2GitHub+2arXiv
- End-to-end ML pipeline and Streamlit dashboard for loan default prediction using XGBoost and Random Forest GitHub+1Medium+1GitHub+2MDPI+2GitHub+2GitHubGitHub+2GitHub+2GitHub+2arXiv
- vasudevsinghal/Loan-Default-Prediction
- Data cleaning, feature engineering, and modeling using Decision Trees and Random Forest with scalable Pandas pipelines GitHub
- tysonpond/lending-club-risk
- Includes feature selection, modeling (Logistic, XGBoost), model interpretability notebooks arXiv+15GitHub+15Kaggle+15
- Includes feature selection, modeling (Logistic, XGBoost), model interpretability notebooks arXiv+15GitHub+15Kaggle+15
- JensBender/loan-default-prediction
Focuses on model evaluation, threshold tuning, Random Forest classifier achieving class-1 recall of 0.80 Kaggle+13GitHub+13GitHub+13
3. Machine Learning Project: Student Performance Prediction

Dataset
UCI Student Performance Dataset: 30+ attributes, including demographics, study habits, and three grade levels (G1, G2, G3) for Portuguese and Math subjects GitHub+4GitHub+4GitHub+4GitHub+6archive.ics.uci.edu+6GitHub+6.
Tools
- Python, Pandas, NumPy
- Seaborn, Matplotlib for visualization
- Scikit‑learn (Linear Regression, decision trees, KNN, SVM)
Description
- Import and explore data (student‑mat.csv or student‑por.csv)
- Preprocess: encode categorical features (e.g. sex, studytime), normalize numeric variables, split features/target (predicting G3)
- Perform exploratory data analysis: plot grade distributions, correlation heatmaps, feature relationships
- Train and compare models: Linear Regression, Decision Tree, Random Forest, K‑Nearest Neighbors, SVM
- Feature engineering: include G1 and G2 grades, attendance, health, free time
- Evaluate using RMSE, MAE, R²; apply cross‑validation
- (Optional) Build GUI or CLI to input student attributes and predict final grade
GitHub Source Code Examples
- stefanostsolos/Student-Grade-Prediction:
- Predicts final grade G3 using G1, G2, study time, health, absences
- Multiple models evaluated; includes GUI and terminal versions
- Achieved ~96.6% accuracy with linear regression MediumStack OverflowMedium+5archive.ics.uci.edu+5GitHub+5GitHub+1GitHub+1GitHub+1GitHub+1GitHub
- Predicts final grade G3 using G1, G2, study time, health, absences
- Anitatorki/Data_Preprocessing:
- Data preprocessing and linear regression model for student performance
- Data preprocessing and linear regression model for student performance
Modular Jupyter notebook with evaluation steps GitHub
4. Machine Learning Project: Credit Card Fraud Detection
Dataset
- Kaggle Credit Card Transactions: ~284,807 records with only 492 labeled as fraud (0.172%), featuring PCA-transformed features V1–V28, along with Time and Amount Kaggle+12Kaggle+12Wikipedia+12.
Tools
- Python, pandas, NumPy, Matplotlib, Seaborn
- Scikit‑learn (Isolation Forest, Local Outlier Factor, Random Forest)
- imbalanced‑learn (SMOTE), Joblib for model persistence
Description
- Load dataset, inspect for missing values and fraud class imbalance
- Scale Time and Amount features using StandardScaler
- Apply anomaly detection (Isolation Forest, LOF) and supervised classification (Random Forest, XGBoost)
- Tune model hyperparameters using GridSearchCV and balance data with SMOTE
- Evaluate using AUPRC, ROC-AUC, precision, recall, and F1-score
- Compare supervised vs unsupervised methods to detect fraudulent transactions
- Visualize anomalies and model performance metrics for interpretability
GitHub Source Code Examples
- Pradnya1208/Credit-card-fraud-detection-using-Isolation-Forest-and-LOF
- Unsupervised anomaly detection with Isolation Forest and LOF, including data preprocessing and PCA GitHubWikipedia+3GitHub+3GitHub+3WikipediaarXiv+1GitHub+1Analytics Vidhya
- sabin74/credit_card_fraud_detection
- End-to-end pipeline covering both supervised (Random Forest) and unsupervised methods, plus model export with joblib GitHub
tysonpond/lending-club-risk (comparable in anomaly detection methods)
5. Machine Learning Project: Customer Segmentation (Clustering)
Dataset E-commerce customer transactional data (purchase history, order frequency, recency, monetary value)
- Commonly used example: UCI Online Retail dataset (UK-based retailer, 2010–2011, ~500 k records) Medium+1arXiv+1GitHub
Tools Python, pandas, NumPy
- Scikit‑learn (K-Means), Matplotlib, Seaborn
- Optional: PCA for dimension reduction
Description
- Data cleaning: handle missing values, format dates, aggregate transactional data per customer
- Feature engineering: compute RFM features—Recency, Frequency, Monetary values
- Scaling: normalize RFM features using StandardScaler for equal weighting
- Elbow method & silhouette analysis: determine optimal number of clusters (k)
- Clustering: apply K-Means on scaled features
- Profile segments: analyze each cluster’s spend, recency, behavioral characteristics
- Visualization: plot clusters in 2D with PCA; generate boxplots, bar charts to describe segments
- Actionable outcomes: identify VIP, frequent, and churned customer segments for personalized marketing
GitHub Source Code Examples
- bushra‑ansari/E‑Commerce‑Customer‑Segmentation‑by‑KMeans‑Clustering
- Implements K-Means on e-commerce data, visualizations, cluster analytics arXiv+6GitHub+6GitHub+6GitHub+1GitHub+1GitHub+2Dataquest+2Medium+2Dataquest+4Medium+4Medium+4GitHub+4GitHub+4GitHub+4Dataquest+2GitHub+2Medium+2
- Implements K-Means on e-commerce data, visualizations, cluster analytics arXiv+6GitHub+6GitHub+6GitHub+1GitHub+1GitHub+2Dataquest+2Medium+2Dataquest+4Medium+4Medium+4GitHub+4GitHub+4GitHub+4Dataquest+2GitHub+2Medium+2
- desaishivani/Customer‑Segmentation
- Full RFM + K-Means pipeline with profile analysis and marketing insight mapping GitHub
- Full RFM + K-Means pipeline with profile analysis and marketing insight mapping GitHub
- IamJafar/E‑Commerce‑Customer‑Segmentation
- End-to-end workflow: preprocessing, elbow method, cluster profiling arXiv+11GitHub+11GitHub+11
- End-to-end workflow: preprocessing, elbow method, cluster profiling arXiv+11GitHub+11GitHub+11
- SRIDHAR3131/E‑commerce‑Customer‑Segmentation
- Includes silhouette score and detailed visualizations for cluster validation arXiv+8GitHub+8GitHub+8
6. Machine Learning Project: Sales Forecasting with Time Series
Dataset Retail store sales data: daily/weekly historical sales records from a chain of retail outlets or “Corporation Favorita” (Kaggle M5 dataset), also featuring seasonal components (kaggle.com M5; similar structures in real-world datasets)Includes high-seasonality patterns related to promotions, holidays, and store-level events arXiv+15GitHub+15GitHub+15GitHubGitHub
Tools
- ARIMA and SARIMA (via statsmodels or pmdarima)
- Facebook Prophet (via prophet library) GitHubGitHub+2MachineLearningMastery.com+2GitHub+2
- Python libraries: pandas, NumPy, Matplotlib, Seaborn
- Optional: Docker, Flask/Streamlit for deployment
Project Description
- Data Preparation: Parse OrderDate or ds field, set as index; handle missing dates/values
- Exploratory Data Analysis (EDA): Visualize trend, seasonality, and holiday effects using time-series plots and seasonal decomposition
- Stationarity Testing: Use ADF test to confirm or enforce stationarity via differencing
- ARIMA:
- Select p, d, q using ACF/PACF or auto_arima
- Fit ARIMA / SARIMA models and forecast short-term sales
- Facebook Prophet:
- Encode seasonality, holidays, and changepoints
- Generate medium- to long-term forecasts with uncertainty intervals GitHubGitHub+5GitHub+5Reddit+5
- Model Evaluation: Compare using RMSE, MAE, MAPE on hold-out data
- Visualization: Plot actual vs. predicted values and model components (trend + weekly/annual seasonality)
- Deployment (Optional): Package as API or Streamlit app for live forecasting
GitHub Source Code Examples
- richardmukechiwa/Sales-Forecasting-Time-Series
- ARIMA & Prophet comparison for weekly sales forecasting with full evaluation (RMSE comparison, visualization) arXiv+8MachineLearningMastery.com+8arXiv+8Polzinben+1GitHub+1GitHub+11GitHub+11GitHub+11
- LaurentVeyssier/time-serie-Sales-forecasting-with-Prophet
- Prophet applied to Rossmann Store daily data, with seasonal decomposition, holiday effects, and deployment-ready notebook Polzinben+2GitHub+2MachineLearningMastery.com+2
- Aditya-Kudo/Time-Series-Forecasting-using-ARIMA-and-Prophet
Multi-store superstore dataset using both ARIMA and Prophet to optimize inventory forecasting GitHub+2GitHub+2GitHub+2
7. Machine Learning Project: Stock Price Prediction
Dataset Retrieved using Yahoo Finance API (supports stocks like AAPL, MSFT, etc.) (Medium, GitHub gist: 10mohi6/pred.py)
Tools Python, Scikit‑learn, XGBoost, pandas, NumPy, pandas‑datareader, Matplotlib, seaborn, (optional TensorFlow for hybrid models)
Project Description
- Pull historical stock data using pandas_datareader and Yahoo Finance API
- Feature engineering: create indicators like daily returns, rolling averages (SMA), and Force Index
- Frame as regression (predict closing price) or classification (price up/down next day)
- Train models: XGBoost Regressor for price forecasting; XGBoost Classifier for movement prediction
- Optional hybrid: integrate TensorFlow/Keras models like LSTM or CNN-LSTM with XGBoost stacking arXiv+2arXiv+2GitHub+2Medium+1Gist+1Gist+1GitHub+1GitHub
- Evaluate performance using RMSE/MAE for regression; accuracy, ROC-AUC for classification
- Visualize predictions versus actuals, feature importance, and training loss curves
GitHub Source Code Examples
- lliussalvat/XGBoost‑Stock‑Price‑Prediction
- Stock price forecasting script with XGBoost regressor and model persistence (github.com) GitHub
- vikasharma005/Stock-Price-Prediction
- Streamlit-based SaaS platform for stock analysis, including regression and classification models (github.com) GitHub
- jiewwantan/XGBoost_stock_prediction
Focused on predicting price direction (up/down) using technical indicators and importance plots (github.com) GitHub+1kaggle.com+1
8. Machine Learning Project: Titanic Survival Prediction
Dataset : Titanic dataset from Kaggle (“Machine Learning from Disaster”), containing 891 training samples and key features like Pclass, Age, Sex, Survived for binary classification GitHub+13Kaggle+13GitHub+13.
Tools : Python, Scikit‑learn (Logistic Regression, Random Forest, XGBoost), Pandas, NumPy, Matplotlib, Seaborn.
Description
- Load and preprocess data: impute missing values (Age, Cabin, Embarked), encode categorical variables, scale numeric features.
- Perform exploratory data analysis: visualize survival distributions by Pclass, Sex, and Age; compute correlation matrices.
- Engineer features: create FamilySize, Title from names, cabin groups, and fare bins.
- Train classification models: Logistic Regression, Decision Tree, Random Forest, XGBoost.
- Optimize hyperparameters using GridSearchCV or RandomizedSearchCV.
- Evaluate model performance using accuracy, precision, recall, F1-score, and ROC-AUC.
- Build ensemble models or a voting classifier for improved accuracy.
GitHub Source Code Examples
- agconti/kaggle‑titanic: A well-maintained notebook with data cleaning, feature engineering, model training, and evaluation using Scikit-learn GitHubGitHub+1GitHub+1GitHub.
- rubydamodar/Titanic‑Survival‑Prediction: Clean pipeline with visualization and model selection; achieves approximately 80% accuracy GitHub+6GitHub+6GitHub+6.
MrAnkitGupta/titanic‑survival‑prediction‑93‑xgboost: Ensemble modeling with Logistic Regression, Random Forest, and XGBoost; reports 93% accuracy
9 Machine Learning Project: Spam Email Detection
Dataset : SpamAssassin Public Corpus: labeled spam vs. ham emails widely used in research and training models arXiv+13Stack Overflow+13GitHub+13
Tools : Python, Scikit‑learn (Multinomial Naive Bayes or SVM)
- pandas, NumPy, Matplotlib, Seaborn
- CountVectorizer/Tf‑IDF (from Scikit‑learn), NLTK for text preprocessing
Description
- Collect and preprocess emails (strip headers, lowercase, remove HTML/tokens, stop words, lemmatization).
- Extract features: utilize CountVectorizer or TF‑IDF to convert email text into feature vectors.
- Split dataset into train/test sets using stratified sampling.
- Train Gaussian/Multinomial Naive Bayes or SVM classifier.
- Evaluate using accuracy, confusion matrix, precision, recall, F1‑score.
- (Optional) Deploy via Flask or Streamlit as a web-based spam detector application.
GitHub Source Code Examples
- GauravG‑20/Spam‑Email‑Detection‑using‑MultinomialNB — features full Naive Bayes workflow with CountVectorizer and a deployed Streamlit app; ~95% accuracy GitHub+3GitHub+3Medium+3GitHub+2GitHub+2Cloud Wizard Inc.+2GitHub+1GitHub+1GitHub
- SrujanPR/Spam‑Email‑Classifier — processes email subject lines using Naive Bayes and Flask for a web interface GitHub+3GitHub+3GitHub+3
- ElisaCovato/Spam‑Classifier — utilizes the SpamAssassin dataset with multiple algorithms and performance plots in Jupyter Notebooks GitHub+9GitHub+9GitHub+9
MoazAshraf/Spam‑Classifier — covers preprocessing, bag-of-words, classifier selection (SGD, SVM, Random Forest) using SpamAssassin data GitHub+11GitHub+11Medium+11
10. Machine Learning Project: Heart Disease Prediction
Dataset : UCI Heart Disease Dataset: Contains 14 key medical attributes (age, sex, chest pain, blood pressure, cholesterol, etc.) used for diagnosing heart disease presence or absence. GitHub+15archive.ics.uci.edu+15GitHub+15
Tools Python (Scikit‑learn — Logistic Regression, Random Forest, XGBoost)
- pandas, NumPy, Matplotlib, Seaborn
- Optional: SHAP or ELI5 for explainability
Description
- Load and clean the dataset: handle missing values and encode categorical features (“chest pain”, “thal”, etc.).
- Conduct exploratory data analysis: correlation matrices, feature distribution plots, and heart-disease ratio analysis.
- Perform feature selection or engineering (e.g., binning cholesterol levels, interaction terms).
- Train and compare models: Logistic Regression, Random Forest, XGBoost.
- Optimize hyperparameters using cross-validation (GridSearchCV).
- Evaluate using accuracy, ROC‑AUC, precision, recall, and F1‑score.
- (Optional) Build a Streamlit app or Flask API for real-time disease prediction and deploy it via Heroku/GCP.
GitHub Source Code Examples
- surdebmalya/Heart‑Disease‑UCI: Utilizes Random Forest and Logistic Regression to achieve ~88.5% test accuracy. Includes model evaluation and visualizations. arXiv+2ScienceDirect+2GitHub+2GitHubGitHub+1GitHub+1GitHubGitHub
- najeebuddinm98/xgboost_heartdisease_pred: Implements XGBoost classifier on the same dataset. arXiv+2GitHub+2ProjectPro+2
- sounakss7/Heart‑Disease‑Prediction‑Using‑Random‑Forest‑Classifier: Features a full pipeline with preprocessing, modeling, and a deployed Streamlit web interface. arXiv+15GitHub+15GitHub+15
- Vedant‑S/Heart‑Disease‑Classification_Random‑Forest: Focuses on Random Forest classification achieving ~95% accuracy using feature selection. GitHub
divyar2630/UCI‑Heart‑Disease: Combines EDA and Logistic Regression with comprehensive reporting. GitHub+2GitHub+2GitHub+2
11. Machine Learning Project: Employee Attrition Prediction
Dataset
- IBM HR Analytics Employee Attrition Data (Kaggle): 1,470 records with 35 variables on employee demographics, job roles, satisfaction levels, and attrition status printalect.github.io+15inseaddataanalytics.github.io+15GitHub+15
Tools
- Python, Scikit‑learn (Decision Tree, Logistic Regression, Random Forest)
- pandas, NumPy, Matplotlib, Seaborn
- Optional: XGBoost, SHAP/ELI5 for model explainability
Project Description
- Load dataset and handle missing values
- Encode categorical variables (Attrition, BusinessTravel, EducationField, etc.)
- Analyze features through EDA: correlation heatmaps, distribution plots, attrition rate by department and age GitHub+5GitHub+5arXiv+5Medium+1GitHub+1dr.lib.iastate.edu+4inseaddataanalytics.github.io+4GitHub+4
- Engineer new features (e.g., tenure groupings, income-to-age ratio)
- Train classification models: Decision Tree, Random Forest, Logistic Regression, optionally XGBoost
- Address class imbalance with techniques like undersampling or SMOTE
- Tune model hyperparameters via cross-validation
- Evaluate performance using accuracy, precision, recall, F1-score, ROC-AUC
- Deploy via Streamlit or Flask for internal HR risk dashboard
GitHub Source Code Examples
- Niranjankumar‑c/HRAnalyticsEmployeeAttrition
- shantanu1109/IBM‑HR‑Analytics‑Employee‑Attrition‑and‑Performance‑Prediction
- Implements multiple classifiers (Logistic Regression, Random Forest, XGBoost, AdaBoost), detailed EDA, and model comparison arXiv+15GitHub+15GitHub+15Medium+3GitHub+3GitHub+3
- sanithps98/HR‑Analytics‑and‑Employee‑Attrition‑Prediction
- Adds GUI using Tkinter, focused on visual VIP insights and model accuracy YouTube+4GitHub+4GitHub+4
- francescogemignani/IBM‑HR‑Employee‑Attrition
Includes Decision Trees, Random Forest, clustering, and association rule mining for deeper insight GitHub+1printalect.github.io+1
12. Machine Learning Project: Electricity Price Forecasting

Dataset
- Australian Energy Market Operator (AEMO) 30-minute interval electricity prices for 2018 (Queensland, NSW) (GitHub repo pratyush‑prateek/electricity_price_forecasting_) GitHub+8GitHub+8GitHub+8
Tools
- Python, Pandas, NumPy
- Statsmodels for ARIMA/SARIMA
- LSTM (via TensorFlow or Keras) for deep learning
- Matplotlib, Seaborn for time-series visualization
- Optionally, hybrid models: GRU, CNN-LSTM, XGBoost integration arXiv+7GitHub+7GitHub+7arXiv
Description
- Load AEMO price data at 30-minute granularity and perform date-time indexing.
- Conduct EDA to visualize trends, seasonal cycles (daily, weekly), and holiday effects Wikipedia.
- Test stationarity (ADF test) and apply differencing as needed for ARIMA modeling.
- Fit ARIMA/SARIMA models using Statsmodels or pmdarima’s auto_arima.
- Build LSTM networks: architecture with sequence-to-one forecasting; optionally include CNN or GRU layers for feature extraction. GitHubGitHub
- Compare model performance (ARIMA vs LSTM) using RMSE, MAE, MAPE.
- (Optional) Explore hybrid ensembles (e.g., LSTM + XGBoost) and advanced architectures like attention‑LSTM. GitHub+2GitHub+2MDPI+2
- Visualize forecasts vs actuals, including confidence intervals and error analysis.
GitHub Source Code Examples
- pratyush‑prateek/electricity_price_forecasting_ – ARIMA-based forecast on Australian Energy Market data with 30‑minute granularity and EDA pipelines arXiv+9GitHub+9Wikipedia+9
- blentley/ForecastingElectricityDemand – LSTM model on NEM demand (proxy for pricing), using temperature and demand correlations GitHub+2GitHub+2jamie cryan+2
dfavenfre/electricity‑price‑forecasting – Hybrid approach combining XGBoost and LSTM for hourly price prediction (EXIST market) GitHub+1GitHub+1
Deep Learning Projects
Image Classification with Convolutional Neural Networks (CNNs)
Dataset
- CIFAR-10 (or optionally MNIST): 60,000 color images (10 classes, e.g., airplane, bird, cat) at 32×32 resolution. For MNIST, 70,000 grayscale digits (0–9). GitHub+9GitHub+9GitHub+9
Tools
- Python | TensorFlow / Keras | NumPy, pandas
- Matplotlib, Seaborn for visualization
- Optional: Data augmentation, EarlyStopping callback for model tuning
Description
- Load and preprocess the dataset (normalize pixel values between 0–1)
- Visualize sample images and verify class distribution
- Build a CNN architecture with convolution + pooling layers, dropout, and softmax output
- Configure data augmentation (rotation, shift, flip) for robustness
- Train the model using categorical_crossentropy loss and monitor validation accuracy
- Apply EarlyStopping and ModelCheckpoint callbacks
- Evaluate model on test set and generate confusion matrix
- (Optional) Improve performance using transfer learning (e.g., MobileNetV2, ResNet), hyperparameter tuning, and deployment in Streamlit or TensorFlow Serving
GitHub Source Code Examples
- PatrickSVM/CIFAR10-Image-Classification-with-CNN
- Custom CNN achieving over 89% test accuracy; includes ELU activation, Batch Normalization, Dropout, and EarlyStopping GitHub+5GitHub+5GitHub+5GitHub+1GitHub+1GitHub+2TensorFlow+2GitHub+2TensorFlow+2GitHub+2GitHub+2GitHub+8GitHub+8GitHub+8
- Custom CNN achieving over 89% test accuracy; includes ELU activation, Batch Normalization, Dropout, and EarlyStopping GitHub+5GitHub+5GitHub+5GitHub+1GitHub+1GitHub+2TensorFlow+2GitHub+2TensorFlow+2GitHub+2GitHub+2GitHub+8GitHub+8GitHub+8
- kolbydboyd/CIFAR-10-Image-Classification-using-TensorFlow-and-Keras
- Step-by-step CNN implementation using TensorFlow Keras API; includes data preprocessing, training, evaluation, and visualization GitHub+2GitHub+2GitHub+2
- mohd-faizy/02P_Project_Image_Classification_with_CNNs_using_Keras
Keras-based project trained on CIFAR-10 with 3-class subset, early stopping, accuracy ~91.2% en.wikipedia.org+12GitHub+12YouTube+12
Face Mask Detection System
Dataset
- Custom dataset: Images labeled as “with_mask” and “without_mask” (e.g., 690 and 686 images, respectively) .PyImageSearch+1SpringerLink+1
Tools
- Python
- OpenCV
- TensorFlow / Keras
- MobileNetV2 architecture
- Streamlit (optional, for deployment)
Description
- Data Preparation: Collect and preprocess images, ensuring balanced classes and proper labeling.
- Model Architecture: Implement MobileNetV2 for feature extraction, followed by dense layers for classification.
- Training: Compile the model with appropriate loss functions and optimizers, then train using the prepared dataset.
- Evaluation: Assess model performance on a separate test set, aiming for high accuracy.
- Deployment: Integrate the model with OpenCV for real-time face detection and mask classification.
- Optional: Use Streamlit to create a user-friendly interface for mask detection.GitHub
GitHub Source Code Examples
- chandrikadeb7/Face-Mask-Detection: A comprehensive implementation using OpenCV and TensorFlow/Keras for both static and real-time mask detection.
- ankitrajput77/FaceMaskDetection: Features a real-time mask detection system with 96% accuracy, utilizing Streamlit for deployment.
- Piyush2912/Real-Time-Face-Mask-Detection: Employs OpenCV DNN, TensorFlow, Keras, and MobileNetV2 for efficient mask detection.
RITIK-12/Face-Mask-Detector: Demonstrates real-time mask detection using OpenCV and TensorFlow. GitHubGitHub
Emotion Recognition from Images
Dataset
- FER-2013: A dataset containing 35,887 labeled 48×48 grayscale face images categorized into seven emotions: anger, disgust, fear, happiness, sadness, surprise, and neutral. ResearchGate+4GitHub+4GitHub+4
Tools
- Python
- TensorFlow / Keras
- OpenCV
- Grad-CAM (for visualizing model decisions)
- Flask (for real-time deployment)
Description
- Data Preprocessing: Normalize pixel values to the range [0, 1], resize images to 48×48 pixels, and perform data augmentation (e.g., rotations, flips) to enhance model generalization.
- Model Architecture: Design a Convolutional Neural Network (CNN) with multiple convolutional layers followed by max-pooling layers, a flattening layer, and dense layers leading to a softmax output layer.
- Training: Compile the model using categorical cross-entropy loss and an appropriate optimizer (e.g., Adam). Train the model on the FER-2013 dataset, monitoring accuracy and loss.
- Evaluation: Assess model performance on a separate test set, aiming for high accuracy and low loss.
- Visualization: Utilize Grad-CAM to generate heatmaps highlighting the regions of the face the model focuses on when making predictions.
- Deployment: Implement a Flask application to serve the trained model, enabling real-time facial emotion recognition via webcam input.GitHub
GitHub Source Code Examples
- MeB4You/FER2013: Features a custom ResNet18 architecture trained on the FER-2013 dataset with improved labeling. Includes real-time webcam emotion detection using Flask.
- baotramduong/Facial-Expression-Recognition-with-CNN-Grad-CAM-and-OpenCV: Demonstrates a CNN model trained on FER-2013, with Grad-CAM visualizations and Flask deployment for real-time emotion detection.
oarriaga/face_classification: Provides a real-time face detection and emotion classification system using FER-2013, with a Keras CNN model and OpenCV.GitHubGitHub+1GitHub+1
Neural Style Transfer Project
Dataset:
- Custom image inputs (users provide their own content and style images)
Tools:
- PyTorch
- Python libraries for image processing (Pillow, OpenCV)
Description:
- Neural Style Transfer is a deep learning technique that blends the content of one image with the style of another.
- The project uses convolutional neural networks (CNNs) to extract content and style representations from images.
- It optimizes an output image to simultaneously match the content features of the content image and the style features of the style image, creating visually stunning artistic renditions.
- This technique is widely used in digital art and photo editing applications.
Key Features:
- Input any content and style images for custom artwork generation.
- Use pretrained CNN models like VGG19 for feature extraction.
- Implement loss functions including content loss and style loss for training.
- Output high-resolution stylized images.
- Option to tweak style weights for more or less stylistic influence.
GitHub Source Code Examples:
AI-Based Image Caption Generator
Dataset:
- Flickr8k Dataset
- MSCOCO (Microsoft Common Objects in Context) Dataset
Tools:
- Convolutional Neural Networks (CNN) for image feature extraction
- Long Short-Term Memory (LSTM) networks for natural language generation
- Python, TensorFlow or PyTorch
Description:
- This project builds an AI model that automatically generates descriptive captions for images by combining computer vision and natural language processing (NLP).
- The CNN extracts meaningful features from input images, while the LSTM network generates coherent sentences word-by-word based on those features.
- It enables applications such as automated image tagging, accessibility improvements, and content summarization.
- The model is trained on large-scale image-caption paired datasets like Flickr8k and MSCOCO to learn diverse and context-aware captions.
Key Features:
- End-to-end pipeline combining CNN for visual understanding and LSTM for language modeling.
- Supports generating multiple captions per image using beam search techniques.
- Customizable vocabulary and pre-processing for natural language accuracy.
- Evaluation using BLEU score and other metrics for caption quality.
- Can be extended for multilingual captioning or real-time image description.
GitHub Source Code Examples:
Autonomous Vehicle Lane Detection
Dataset:
- Video footage from dashcams or publicly available driving datasets such as Udacity Self-Driving Car Dataset
Tools:
- OpenCV for image processing and computer vision tasks
- Deep Learning frameworks like TensorFlow or PyTorch for lane segmentation
- Python
Description:
- This project involves building a system that can detect road lanes in real-time video streams, crucial for autonomous vehicle navigation and driver assistance systems.
- Traditional computer vision techniques combined with deep learning models are used to identify lane markings under varying lighting and weather conditions.
- The solution applies image filtering, edge detection, perspective transforms, and deep neural networks to segment lane lines accurately.
- It is applicable in self-driving car simulations, driver safety systems, and traffic monitoring.
Key Features:
- Real-time lane detection using video feed input.
- Combination of OpenCV image processing (Canny edge detection, Hough transform) and CNN-based segmentation.
- Robust performance under different road and weather scenarios.
- Visualization of detected lanes on original video frames.
- Easily extendable to detect multiple lane types and road signs.
GitHub Source Code Examples:
Handwritten Equation Solver
Dataset: IAM Handwriting Database Math OCR Datasets such as CROHME (Competition on Recognition of Online Handwritten Mathematical Expressions)
Tools: Deep Optical Character Recognition (OCR) frameworks (e.g., Tesseract, PaddleOCR)
- Symbolic Math Libraries (e.g., SymPy)
- Python, TensorFlow or PyTorch for deep learning models
Description:
- This project focuses on developing an AI system that can accurately recognize handwritten mathematical expressions and solve them automatically.
- The process involves detecting handwritten symbols using deep OCR techniques and interpreting their mathematical meaning via symbolic computation libraries.
- It integrates computer vision for character segmentation with mathematical logic to provide solutions to complex equations.
- Useful for educational tools, math tutoring apps, and automated grading systems.
Key Features:
- Handwritten math symbol detection and recognition using deep OCR.
- Parsing recognized symbols into valid mathematical expressions.
- Automated equation solving with symbolic math libraries like SymPy.
- Supports arithmetic, algebraic, and calculus expressions.
- User-friendly interface for inputting handwritten equations via images or touchscreens.
GitHub Source Code Examples:
COVID-19 Chest X-Ray Classification
Dataset:
- Open COVID-19 Radiography Dataset (COVID-19 Radiography Database)
Tools:
- Convolutional Neural Networks (CNN)
- Transfer Learning techniques using pre-trained models (e.g., ResNet, VGG, Inception)
- Python, TensorFlow, Keras
Description:
- This project focuses on classifying chest X-ray images to identify COVID-19 infections.
- Leveraging CNN architectures combined with transfer learning enables efficient training even with limited labeled COVID-19 data.
- The model distinguishes between normal, pneumonia, and COVID-19 affected lungs using radiographic images.
- It provides a crucial tool for assisting radiologists and healthcare professionals with fast and automated diagnosis.
- The project includes data preprocessing, model training, evaluation metrics, and deployment strategies.
Key Features:
- Utilizes transfer learning for enhanced model accuracy with limited datasets.
- Multi-class classification: Normal, COVID-19 positive, and Pneumonia.
- Data augmentation techniques to increase dataset variability.
- Confusion matrix and performance metrics visualization.
- Ready-to-use Python notebooks and modular source code for easy customization.
GitHub Source Code Examples:
GANs for Image Generation
Dataset:
- CelebA Dataset (Large-scale CelebFaces Attributes Dataset)
- Custom datasets for specific object categories
Tools:
- TensorFlow or PyTorch
- Generative Adversarial Networks (GANs) framework
- Python
Description:
- This project involves training Generative Adversarial Networks (GANs) to create realistic images from noise inputs.
- GANs consist of two neural networks, a generator and a discriminator, that compete to improve image quality progressively.
- Common applications include generating realistic human faces, artwork, or objects that do not exist in the original dataset.
- The project includes data preprocessing, GAN architecture setup, training procedures, and evaluation of generated images.
- Techniques like DCGAN, StyleGAN, or CycleGAN can be explored to enhance generation quality.
Key Features:
- Implementation of GAN architecture including generator and discriminator networks.
- Use of CelebA dataset for realistic face generation.
- Training on custom datasets for diverse image generation tasks.
- Visualization of generated images after every training epoch.
- Integration of loss functions and optimization for stable GAN training.
GitHub Source Code Examples:
Speech Emotion Recognition
Dataset:
- RAVDESS (Ryerson Audio-Visual Database of Emotional Speech and Song)
- TESS (Toronto Emotional Speech Set)
Tools:
- Python libraries: Librosa for audio processing
- Deep Learning models: Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) networks
- TensorFlow / Keras or PyTorch frameworks
Description:
- This project focuses on detecting and classifying human emotions from speech audio samples using deep learning techniques.
- Audio preprocessing involves extracting features like Mel-frequency cepstral coefficients (MFCCs) using Librosa.
- CNNs are used to learn spatial features from spectrograms, while LSTMs capture temporal dependencies in audio signals.
- The model classifies emotions such as happiness, sadness, anger, fear, surprise, and neutral tone.
- Applications include call center analytics, human-computer interaction, and mental health monitoring.
- The project involves data loading, feature extraction, model training, evaluation, and deployment-ready scripts.
Key Features:
- Audio feature extraction using Librosa’s MFCC and chroma features.
- Hybrid CNN-LSTM architecture for enhanced emotion recognition accuracy.
- Use of balanced datasets (RAVDESS and TESS) to improve generalization.
- Real-time emotion recognition demo setup.
- Model performance evaluation with confusion matrix and classification reports.
GitHub Source Code Examples:
NLP (Natural Language Processing) Projects Sentiment Analysis on Social Media Tweets

Dataset:
- Twitter API (for real-time tweet extraction)
- Kaggle Twitter Sentiment Datasets (e.g., Sentiment140, Twitter US Airline Sentiment)
Tools:
- Natural Language Toolkit (NLTK) for text preprocessing
- TextBlob for sentiment polarity and subjectivity analysis
- Scikit-learn for machine learning classification models such as Logistic Regression, SVM, or Random Forest
- Python for scripting and data manipulation
Description:
- This project involves building a sentiment classification system to analyze public opinions from Twitter data.
- Tweets are collected using Twitter API or sourced from curated Kaggle datasets.
- Text preprocessing includes tokenization, stop word removal, and stemming using NLTK.
- Sentiment polarity is initially gauged using TextBlob, which assigns positive, neutral, or negative labels.
- Machine learning models are trained on labeled data to improve classification accuracy.
- The system can be used for brand monitoring, market analysis, or social campaign evaluation.
- The project includes data collection, cleaning, feature extraction (TF-IDF), model training, testing, and deployment-ready code.
Key Features:
- Real-time tweet collection using Twitter API integration.
- Robust text preprocessing pipeline with NLTK.
- Multiple sentiment classification algorithms implemented and compared.
- Visualization of sentiment trends over time using Matplotlib or Seaborn.
- Comprehensive evaluation with accuracy, precision, recall, and F1-score metrics.
GitHub Source Code Examples:
Resume Parser Using NLP
Dataset:
- Sample Resumes Dataset (publicly available or custom collections of resumes in PDF or text format)
Tools:
- SpaCy for natural language processing and entity recognition
- Regex (Regular Expressions) for pattern matching in text extraction
- Python for scripting, data processing, and automation
Description:
- This project automates the extraction of key information from resumes, such as candidate skills, educational background, work experience, and contact details.
- Utilizes SpaCy’s Named Entity Recognition (NER) models to identify entities like degrees, institutions, job titles, and skills.
- Regular expressions help detect phone numbers, emails, and dates.
- Parses diverse resume formats, including PDF and DOCX, converting them to text for analysis.
- Output is structured into standardized JSON or CSV formats for easy integration with HR management systems.
- Helps HR teams efficiently screen resumes and shortlist candidates without manual effort.
- Includes data preprocessing, NLP pipeline creation, entity extraction, and performance evaluation.
Key Features:
- Automated parsing and categorization of resume content.
- Robust handling of varied resume formats and layouts.
- Integration of SpaCy custom pipelines with regex-based enhancements.
- Export results in structured data formats for easy database insertion.
- Visualization dashboards showing skill frequency and education trends (optional).
GitHub Source Code Examples:
Spam Email Classifier
Dataset:
- Enron Spam Dataset (publicly available collection of emails labeled as spam or ham)
Tools:
- Scikit-learn for machine learning algorithms and model training
- NLTK (Natural Language Toolkit) for text preprocessing, tokenization, and stopword removal
- Python for scripting and pipeline integration
Description:
- This project builds a robust spam email classifier to automatically detect and filter unwanted emails from user inboxes.
- Utilizes natural language processing techniques including tokenization, stemming, and stopword removal using NLTK.
- Feature extraction with TF-IDF or Count Vectorizer to convert emails into numerical representations.
- Trains classification models such as Naive Bayes, Logistic Regression, or Support Vector Machines (SVM) using Scikit-learn.
- Evaluates model performance with metrics like accuracy, precision, recall, and F1-score.
- Can be integrated with email clients or services to improve email sorting and user experience.
- Demonstrates end-to-end pipeline from data preprocessing, model training, to prediction.
Key Features:
- Preprocessing of raw email text for effective feature extraction.
- Multiple classifier comparison for optimal spam detection.
- Model evaluation using confusion matrix and ROC curves.
- Easy adaptability to new datasets and real-world inboxes.
- Can be extended with deep learning models for enhanced performance.
GitHub Source Code Examples:
Text Summarizer Using Transformers
Dataset:
- News Articles datasets such as CNN/Daily Mail, XSum, or any custom collection of long text documents suitable for summarization.
Tools:
- HuggingFace Transformers library for access to pretrained models like BERT, BART, or T5
- Python for scripting and data handling
- PyTorch or TensorFlow backend (depending on model)
Description:
- This project develops an abstractive text summarization system that generates concise summaries by understanding the context of the input text rather than just extracting sentences.
- Utilizes transformer-based models such as BERT, BART, or T5 known for their strong performance in natural language understanding and generation tasks.
- Implements fine-tuning on datasets of news articles or custom text corpora to adapt the model to specific domains or writing styles.
- Incorporates preprocessing steps such as tokenization, padding, and attention mask generation compatible with transformer architectures.
- Evaluates summary quality using metrics like ROUGE scores, comparing generated summaries to human-written references.
- Deployable as an API or integrated into applications for automatic content summarization in news aggregation, research, or social media.
Named Entity Recognition (NER) System
Dataset:
- CoNLL-2003 dataset, a widely used benchmark for NER tasks, containing annotated entities such as persons, organizations, locations, and miscellaneous entities.
- SpaCy’s built-in corpora or other open-source annotated text corpora for NER training and evaluation.
Tools:
- SpaCy: An industrial-strength NLP library with pretrained models and easy customization for NER.
- NLTK: For preprocessing, tokenization, and text handling.
- Pythn: Primary programming language for model implementation and integration.
Description:
- Develops a Named Entity Recognition system capable of identifying and classifying key entities like names of people, organizations, locations, dates, and other domain-specific entities within unstructured text.
- Leverages SpaCy’s pretrained transformer-based NER models or trains custom models using annotated datasets to improve domain-specific recognition accuracy.
- Implements data preprocessing including tokenization, POS tagging, and chunking to enhance model performance.
- Supports both rule-based and machine learning approaches, enabling hybrid NER systems adaptable to various industries like finance, healthcare, and legal.
- Evaluates performance using precision, recall, and F1-score metrics on standard datasets such as CoNLL-2003.
- Can be integrated into larger NLP pipelines for tasks like information extraction, question answering, or document summarization.
Key Features:
- Accurate entity detection using state-of-the-art SpaCy models.
- Easy fine-tuning for custom domains with additional training data.
- Supports multiple entity types with high flexibility.
- Integrates seamlessly with Python NLP workflows.
- Provides visualization of entities for better interpretability.
GitHub Source Code Examples:
Language Translation App
Dataset:
- Europarl Corpus: A parallel corpus extracted from the proceedings of the European Parliament, widely used for machine translation tasks.
- Multi30k Dataset: Contains image captions in multiple languages, useful for multimodal translation and text translation tasks.
Tools:
- Sequence-to-Sequence (Seq2Seq) Models: Encoder-decoder architectures essential for language translation tasks.
- TensorFlow: Deep learning framework used to build and train neural networks.
- LSTM (Long Short-Term Memory): Recurrent neural network variant that handles sequential data and retains long-term dependencies, ideal for text translation.
Description:
- This project involves building a deep learning-based language translation application that translates text from one language to another (e.g., English to French, German to English).
- Utilizes Seq2Seq models with attention mechanisms to improve translation accuracy by focusing on relevant parts of the input sentence during decoding.
- Incorporates LSTM layers for capturing temporal dependencies in sequences, improving translation quality over traditional models.
- Trains models on large parallel corpora such as Europarl or Multi30k datasets to learn mappings between source and target languages.
- Supports preprocessing steps including tokenization, padding, and vocabulary indexing for efficient model training.
- Includes evaluation metrics like BLEU score to measure translation performance.
- Deplos the trained model within a web or mobile application interface for real-time translation.
Key Features:
- Neural machine translation using Seq2Seq and attention.
- Support for multiple language pairs depending on dataset availability.
- End-to-end training and evaluation pipeline.
- Modular codebase allowing customization for different languages or datasets.
- Potential integration with APIs for real-world applications.
GitHub Source Code Examples:
Fake News Detection
Dataset:
- Kaggle Fake News Dataset: A widely used dataset containing labeled news articles categorized as real or fake, used for training and evaluating fake news detection models.
Tools:
- TF-IDF (Term Frequency-Inverse Document Frequency): A text vectorization technique that converts text documents into numerical feature vectors by evaluating word importance relative to a corpus.
- Logistic Regression: A supervised machine learning algorithm for binary classification, ideal for predicting whether a news article is fake or real based on extracted features.
Description:
- The Fake News Detection project aims to classify news articles as either real or fake by analyzing the textual content.
- Utilizes TF-IDF to transform raw news text into weighted feature vectors that highlight important terms while reducing the impact of common words.
- Employs Logistic Regression to learn patterns distinguishing fake news from authentic news based on the TF-IDF features.
- Includes preprocessing steps such as tokenization, stop-word removal, and text normalization to clean the input data.
- Evaluates model performance using accuracy, precision, recall, and F1-score metrics to ensure reliable detection.
- Can be extended with additional NLP techniques such as n-grams, word embeddings, or advanced classifiers for improved accuracy.
- Useful for media platforms, social networks, and users to identify misinformation and promote trustworthy content.
Key Features:
- Binary classification model for fake vs. real news detection.
- Text preprocessing and feature extraction with TF-IDF.
- Simple yet effective Logistic Regression classifier.
- Evaluation using comprehensive metrics for balanced model assessment.
- Easy integration with web apps or content moderation tools.
GitHub Source Code Examples:
Question Answering System (like SQuAD)
Dataset:
- Stanford Question Answering Dataset (SQuAD): A large-scale reading comprehension dataset consisting of questions posed on Wikipedia articles, where the answer to each question is a segment of text from the corresponding passage.
Tools:
- BERT (Bidirectional Encoder Representations from Transformers): A powerful transformer-based model pre-trained on large corpora for various NLP tasks, including question answering.
- HuggingFace Transformers: An open-source library providing easy access to pre-trained models like BERT for fine-tuning and deployment.
Description:
- This project builds a Question Answering (QA) system that reads a given text passage and extracts the exact answer to user questions.
- Utilizes BERT’s deep bidirectional transformer architecture to understand the context of both the question and the passage for accurate answer extraction.
- Fine-tunes a pre-trained BERT model on the SQuAD dataset to improve performance on the QA task.
- Supports extractive QA, where the model predicts the start and end positions of the answer span within the passage.
- Implements data preprocessing steps such as tokenization and input formatting compatible with transformer models.
- Provides an interactive interface or API to query the system with custom questions and receive precise answers.
- Evaluates model accuracy using metrics like Exact Match (EM) and F1 score, benchmarked against the SQuAD leaderboard.
Key Features:
- Extractive question answering leveraging state-of-the-art BERT models.
- Fine-tuned on SQuAD, ensuring high accuracy on diverse question types.
- Easy integration with HuggingFace pipeline for inference and deployment.
- Supports natural language queries on any textual data source.
- Useful for building chatbots, virtual assistants, and knowledge retrieval systems.
GitHub Source Code Examples:
Speech-to-Text Transcription
Dataset:
- LibriSpeech: A large corpus of read English speech derived from audiobooks.
- Mozilla Common Voice: An open dataset of diverse voice recordings contributed by users worldwide.
Tools:
- DeepSpeech: An open-source speech-to-text engine based on Baidu’s Deep Speech research paper, utilizing deep neural networks for accurate transcription.
- Wav2Vec2: A state-of-the-art model by Facebook AI for self-supervised speech representation learning, widely used for speech recognition tasks.
Description:
- This project converts spoken language audio into accurate written text using advanced deep learning models.
- Implements end-to-end speech recognition systems leveraging neural networks trained on large speech datasets.
- Utilizes DeepSpeech architecture or Wav2Vec2 pretrained models fine-tuned for transcription accuracy.
- Handles noisy and real-world audio inputs with robust preprocessing and augmentation techniques.
- Incldes features like language modeling, beam search decoding, and error correction to improve transcription quality.
- Provides an API or interface to process live audio streams or audio files for real-time or batch transcription.
- Can be adapted for multilingual speech-to-text systems.
Key Features:
- High accuracy speech recognition using deep neural networks.
- Supports real-time and offline transcription of audio.
- Open-source models with extensive community support.
- Ability to handle diverse audio qualities and accents.
- Suitable for building virtual assistants, transcription services, and accessibility tools.
GitHub Source Code Examples:
Topic Modeling with LDA (Latent Dirichlet Allocation)
Dataset:
- News groups datasets (e.g., 20 Newsgroups dataset)
- Wikipedia dumps or large-scale text corpora
Tools:
- Gensim: A robust Python library for topic modeling and document similarity analysis.
- LDA (Latent Dirichlet Allocation): A popular unsupervised machine learning algorithm used to identify abstract topics in large collections of text.
Description:
- This project applies LDA to extract latent topics from large text datasets such as news articles or encyclopedia dumps.
- Enables uncovering hidden thematic structures and grouping documents by topic without labeled data.
- Useful for summarizing, categorizing, and organizing large volumes of unstructured text.
- Includes preprocessing steps like tokenization, stopword removal, and lemmatization to prepare text data.
- Visualizes topics using word clouds, pyLDAvis interactive plots, and coherence scores to evaluate topic quality.
- Can be adapted for recommendation systems, search optimization, and content analysis.
Key Features:
- Efficient unsupervised topic extraction for NLP projects.
- Interactive visualizations to interpret topic distributions.
- Supports scalable text data processing.
- Improves understanding of large text corpora for business intelligence.
- Integrates with downstream NLP workflows for text classification and summarization.
GitHub Source Code Examples:
Beginner-Friendly & Final Year Projects
Whether you’re just starting your data science journey or need a final-year academic project, the following ideas are practical, impressive, and easy to scale.
🎯 Beginner Data Science Projects
Iris Flower Classification Project
Dataset:
- Iris Dataset (UCI Machine Learning Repository)
- A widely-used benchmark dataset for beginner machine learning tasks.
Tools Used:
- Scikit-learn for building and evaluating classification models
- Pandas for data manipulation and analysis
- Matplotlib and Seaborn for visualization (optional for insights)
Description:
- This classic machine learning project involves predicting the species of iris flowers (Setosa, Versicolor, Virginica) based on their sepal length, sepal width, petal length, and petal width.
- It serves as an excellent introduction to supervised learning and classification techniques.
- The project includes steps such as data preprocessing, EDA (exploratory data analysis), model training, accuracy evaluation, and visualization of decision boundaries.
- Algorithms commonly used: Logistic Regression, Decision Trees, KNN, SVM, and Random Forest.
Key Highlights:
- Simple yet powerful classification problem ideal for ML beginners.
- Learn model training, testing, and evaluation in a structured workflow.
- Great for building your portfolio with practical machine learning skills.
- Demonstrates fundamental concepts like feature selection and cross-validation.
- Easy to expand into multiclass classification and ensemble learning.
GitHub Source Code Examples:
Titanic Survival Prediction – Machine Learning Project
Dataset:
- Kaggle Titanic Dataset
- One of the most famous beginner datasets for binary classification problems in machine learning.
Tools Used:
- Scikit-learn for model building and evaluation
- Pandas for data manipulation and cleaning
- Seaborn & Matplotlib for data visualization
- Optional: XGBoost or LightGBM for improved performance
Project Description:
- This project focuses on predicting survival outcomes of Titanic passengers based on features like age, sex, passenger class (Pclass), family size, fare, and more.
- It is a binary classification problem (Survived or Not Survived).
- The challenge involves handling missing data, feature engineering, and model selection.
- Common ML algorithms applied: Logistic Regression, Random Forest, Decision Tree, and Gradient Boosting.
Key Highlights:
- Ideal for beginners starting with supervised machine learning.
- Emphasizes the importance of data cleaning and preprocessing.
- Feature engineering plays a critical role in boosting model accuracy.
- Good introduction to working with imbalanced datasets.
- Perfect case study for model evaluation techniques like confusion matrix, ROC curve, and cross-validation.
GitHub Source Code Examples:
Stock Price Visualizer – Data Science Project
Dataset:
- Yahoo Finance API via yfinance Python package
- Access real-time and historical stock market data for any listed company (e.g., AAPL, MSFT, TSLA)
Tools Used:
- Pandas – for time-series data manipulation
- Matplotlib and Seaborn – for static and interactive stock price plots
- Optional: Plotly or Bokeh – for dynamic, web-based visualizations
Project Description:
- This project visualizes historical stock prices using interactive and static graphs.
- Users can input a stock ticker symbol, select date ranges, and generate candlestick or line charts.
- The project includes technical indicators such as moving averages, Bollinger Bands, and volume overlays.
- Can be extended into a dashboard or web app using Streamlit or Dash.
Key Features:
- Fetch real-time data using Yahoo Finance API
- Display time-series plots for stock price trends
- Overlay technical indicators (MA, RSI, Bollinger Bands)
- Build interactive visualization tools using Plotly
- Great for practicing data wrangling, time-series analysis, and visual storytelling
GitHub Source Code Examples:
Student Marks Prediction – Data Science Mini Project

Dataset:
- Custom CSV file (e.g., student_scores.csv)
- Or sourced from UCI Machine Learning Repository – Student Performance Data
Tools Used:
- Python
- Pandas – for data loading and preprocessing
- Matplotlib / Seaborn – for visualization
- Scikit-learn – for Linear Regression model building and evaluation
Project Description:
- This beginner-friendly data science project uses linear regression to predict a student’s final exam score based on the number of hours they study.
- It demonstrates the fundamental concept of supervised learning and simple regression modeling.
- This project is ideal for freshers learning Python for data science, and showcases how to handle CSV datasets, split data, train ML models, and evaluate accuracy.
Key Features:
- Reads and cleans student score data from a CSV file
- Builds a linear regression model using Scikit-learn
- Visualizes the correlation between study hours and scores
- Predicts student marks on custom input
- Calculates R² Score and Mean Absolute Error to evaluate performance
GitHub Source Code Examples:
🎓 Final Year Projects (Academic-Level)
Disease Prediction Using Machine Learning
Dataset:
- Healthcare datasets from Kaggle or UCI Machine Learning Repository
- Popular choices include:
- Diabetes Prediction Dataset
- Heart Disease Dataset
- Liver Disease Prediction Dataset
Tools Used:
- Python
- Scikit-learn (Logistic Regression, Decision Trees, Random Forest)
- Streamlit (for real-time web interface)
- Pandas, Matplotlib, Seaborn (for EDA and visualization)
Project Description:
This project focuses on predicting the likelihood of common diseases such as diabetes, heart disease, or liver conditions using supervised machine learning. The model is trained using historical patient data (like age, BMI, blood pressure, glucose levels) and provides a binary prediction: disease or no disease.
You’ll learn how to:
- Clean and preprocess medical datasets
- Perform EDA (Exploratory Data Analysis)
- Train multiple classification models (Logistic Regression, SVM, KNN)
- Evaluate model accuracy with metrics like ROC-AUC, Precision, Recall
- Deploy your prediction system using Streamlit
GitHub Source Code Examples:
Customer Segmentation Using Clustering
Dataset:
- E-commerce customer data from:
- 📊 Kaggle – Mall Customer Segmentation Dataset
- OR custom e-commerce purchase history, demographic, and behavioral data
Tools & Libraries:
- Python, Pandas, Seaborn, Matplotlib
- K-Means Clustering
- Optional: DBSCAN, Hierarchical Clustering for comparison
Project Description:
In this unsupervised machine learning project, you’ll apply K-means clustering to segment customers based on key attributes such as annual income, spending score, age, and behavioral traits.
The goal is to group similar customers together, enabling targeted marketing strategies, personalized offers, and improved customer retention.
Key Steps:
- Data Cleaning & Preprocessing
- Handle missing values, normalize features
- Feature Selection
- Select meaningful attributes (income, spending score, etc.)
- Apply K-Means Clustering
- Use Elbow Method to determine optimal clusters (k)
- VisualizationVisualize clusters using 2D and 3D plots
- Business Interpretation
- Profile each segment: High spenders, low spenders, etc.
GitHub Project Examples:
Simple Chatbot Using NLTK – Rule-Based NLP Mini Project
Dataset:
- Custom Question-and-Answer (Q&A) pairs in plain text or .csv
- Example format:
txt
CopyEdit
Q: What is your name?
- A: I am your virtual assistant.
Tools Used:
- Python
- NLTK (Natural Language Toolkit)
- Regex or tokenization for preprocessing
- Optional: Flask or Streamlit for web deployment
Project Description:
This beginner-level chatbot project uses NLTK to build a rule-based or retrieval-based chatbot that responds to user questions using a predefined set of Q&A pairs. It’s ideal for learning the basics of Natural Language Processing (NLP) and simulating FAQ-based conversation systems.
You’ll learn how to:
- Tokenize user inputs using NLTK
- Match queries using cosine similarity or regex
- Preprocess text (lowercasing, removing punctuation, stemming/lemmatizing)
- Respond accurately from your custom knowledge base
GitHub Source Code Examples:
Credit Card Fraud Detection using Machine Learning
Dataset Source:
- 🗃️ Kaggle – Credit Card Fraud Detection Dataset
- Contains 284,807 transactions including 492 fraudulent ones
- Highly imbalanced dataset (Class 0: legit, Class 1: fraud)
Tools & Techniques Used:
- Python, Pandas, Scikit-learn
- Isolation Forest, Local Outlier Factor (for anomaly detection)
- SMOTE (Synthetic Minority Oversampling Technique) for class balancing
- Optional: XGBoost, Random Forest for improved classification performance
Project Description:
This project focuses on identifying fraudulent transactions from a large, imbalanced financial dataset. Using anomaly detection techniques like Isolation Forest and Local Outlier Factor, the model identifies suspicious behavior patterns that deviate from the norm.
To address class imbalance, SMOTE is used to generate synthetic fraud samples during training.
Project Steps:
- Exploratory Data Analysis (EDA)
- Understand class distribution and feature correlation
- Data Preprocessing
- Normalize features, handle imbalances using SMOTE
- Model Building
- Train models using Isolation Forest and compare with supervised models
- Evaluation Metrics
- Use Precision, Recall, F1-score, and ROC-AUC due to class imbalance
- Visualization
- Use t-SNE or PCA to visualize fraud vs. normal patterns
GitHub Project Repositories:
Real-World Applications:
- Fraud detection in banking and fintech apps
- Real-time transaction monitoring systems
- Risk scoring and compliance tools
- Insurance fraud analytics
Traffic Sign Recognition System
Dataset:
- German Traffic Sign Recognition Benchmark (GTSRB)
- Contains over 50,000 labeled images across 43 traffic sign categories
Tools Used:
- Python
- TensorFlow or Keras for building CNN models
- OpenCV for image preprocessing and real-time detection
- Matplotlib or Seaborn for data visualization
Project Description:
This machine learning project involves building a Convolutional Neural Network (CNN) to classify traffic signs from images using the GTSRB dataset. The trained model can be deployed in real-time environments to assist in autonomous vehicle applications.
Key Steps:
- Data Preprocessing: Resize images to 32×32 pixels, normalize pixel values, and apply data augmentation techniques such as rotation and flipping.
- Model Architecture: Build a CNN using convolutional layers, pooling layers, dropout for regularization, and dense layers for classification.
- Training the Model: Use categorical cross-entropy loss and the Adam optimizer. Evaluate the model on validation data.
- Evaluation: Generate accuracy scores, loss curves, and confusion matrix to analyze classification performance.
- Deployment: Integrate the trained model with OpenCV to detect and classify traffic signs from webcam input in real-time.
GitHub Project Link:
Personality Prediction from Text

Dataset:
- MyPersonality dataset (Facebook personality quiz data)
- Reddit or Twitter user text data for personality inference
Tools Used:
- Natural Language Processing (NLP) libraries: HuggingFace Transformers, SpaCy
- Pretrained language models such as BERT or RoBERTa
- Python for data processing and model implementation
Project Description:
This project focuses on predicting personality traits of users based on their text inputs using advanced NLP techniques. Utilizing models like BERT, the system classifies users into personality categories such as the Big Five traits (Openness, Conscientiousness, Extraversion, Agreeableness, Neuroticism). The approach combines linguistic feature extraction with deep contextual embeddings to improve prediction accuracy.
Key Steps:
- Data Collection: Gather user text data from social media platforms or personality survey datasets.
- Preprocessing: Clean and tokenize text data; remove noise like stop words and punctuation.
- Feature Extraction: Use BERT embeddings to capture semantic context of the text.
- Model Training: Fine-tune pretrained BERT models on labeled personality datasets.
- Evaluation: Measure model performance using accuracy, F1-score, and confusion matrices.
- Deployment: Develop an API or web app for real-time personality trait prediction from input text.
GitHub Project Link:
Facial Expression Detection
Dataset:
- FER2013 Dataset (Facial Expression Recognition 2013)
Tools Used:
- OpenCV for image processing and face detection
- Convolutional Neural Networks (CNN) implemented with TensorFlow/Keras or PyTorch
- Python for model development and training
Project Description:
This project involves building a system to recognize human emotions by analyzing facial expressions in images or video streams. Using the FER2013 dataset, which contains thousands of labeled facial images across multiple emotions (such as happy, sad, angry, surprise, neutral), the CNN model learns to classify these expressions accurately. OpenCV assists in preprocessing by detecting faces and extracting regions of interest before classification.
Key Steps:
- Data Preparation: Load and preprocess images from FER2013, normalize pixel values, and perform data augmentation.
- Face Detection: Use OpenCV’s Haar cascades or DNN modules to detect faces within images or live video frames.
- Model Architecture: Design and train a CNN tailored to facial expression recognition.
- Training: Fine-tune CNN on the FER2013 dataset for emotion classification.
- Evaluation: Assess accuracy using confusion matrices and classification reports.
- Deployment: Implement a real-time facial expression detector using webcam input and OpenCV interface.
GitHub Project Link:
Real-Time Mask Detection App
Dataset:
- OpenCV Face Mask Dataset or custom collected images
Tools Used:
- TensorFlow for deep learning model development
- MobileNet architecture for lightweight and efficient CNN
- OpenCV for real-time video capture and preprocessing
- Python for building and deploying the application
Project Description:
This project builds a real-time face mask detection application designed to identify whether a person is wearing a mask through webcam input. The model is trained using labeled datasets consisting of images with and without masks. Using TensorFlow and the lightweight MobileNet CNN, the application achieves high accuracy while maintaining fast inference speeds suitable for deployment on edge devices or live environments. OpenCV handles face detection and frame preprocessing in real-time, feeding the images to the CNN for mask classification.
Key Steps:
- Data Collection: Use existing OpenCV datasets or collect custom images of masked and unmasked faces.
- Preprocessing: Detect faces in video frames using OpenCV and resize inputs to fit the MobileNet input size.
- Model Training: Train a MobileNet-based CNN classifier on the mask dataset with augmentation techniques.
- Real-Time Detection: Integrate the trained model with OpenCV to process webcam feed and classify mask usage instantly.
- Evaluation: Measure accuracy, precision, recall, and F1-score on test data to validate model performance.
- Deployment: Package the app for easy usage on desktop or mobile platforms.
GitHub Project Link:
Top 50 Machine Learning Projects with Code
Beginner-Level Data Science Projects
1. Iris Flower Classification
- Dataset: Iris Dataset (UCI)
- Tools: Python, Scikit-learn, Pandas
- Description: Classify iris flowers into species based on petal and sepal measurements using classification algorithms like K-Nearest Neighbors and Decision Trees.
- GitHub: Iris Classification Project
2. Titanic Survival Prediction
- Dataset: Titanic Dataset (Kaggle)
- Tools: Python, Scikit-learn, Pandas, Seaborn
- Description: Predict survival outcomes of passengers aboard the Titanic using classification models like Logistic Regression and Random Forest.
- GitHub: Titanic Survival Prediction
3. House Price Prediction
- Dataset: Ames Housing Dataset (Kaggle)
- Tools: Python, Scikit-learn, Pandas
- Description: Predict house prices using regression techniques by analyzing housing features such as area, location, and condition.
- GitHub: House Price Prediction
4. Wine Quality Classification
- Dataset: Wine Quality Dataset (UCI)
- Tools: Python, Scikit-learn
- Description: Classify wine quality ratings based on physicochemical tests using classification algorithms.
- GitHub: Wine Quality Classification
5. Breast Cancer Detection
- Dataset: Wisconsin Breast Cancer Dataset
- Tools: Python, Scikit-learn
- Description: Detect malignant or benign tumors using classification models such as Support Vector Machines and Random Forests.
- GitHub: Breast Cancer Detection
6. Student Performance Predictor
- Dataset: UCI Student Performance Dataset
- Tools: Python, Scikit-learn, Seaborn
- Description: Predict student academic performance based on demographic and school-related features using regression models.
- GitHub: Student Performance Prediction
7. Loan Eligibility Prediction
- Dataset: Lending Club Dataset
- Tools: Python, XGBoost, Pandas
- Description: Predict whether a loan applicant is eligible for loan approval based on financial and demographic data using classification algorithms.
- GitHub: Loan Eligibility Prediction
8. Diabetes Detection
- Dataset: Pima Indians Diabetes Dataset (Kaggle)
- Tools: Python, Scikit-learn
- Description: Predict diabetes occurrence using patient health metrics through classification models like Logistic Regression and Random Forest.
- GitHub: Diabetes Detection
9. Spam Detection (Email/SMS)
- Dataset: SpamAssassin Public Corpus, SMS Spam Collection
- Tools: Python, Naive Bayes, Scikit-learn, NLTK
- Description: Classify messages as spam or not using Natural Language Processing and machine learning classification techniques.
- GitHub: Spam Detection
10. Weather Forecasting
- Dataset: Historical Weather Data (NOAA or OpenWeatherMap)
- Tools: Python, ARIMA, Facebook Prophet
- Description: Forecast temperature and weather conditions using time series analysis and forecasting models.
GitHub: Weather Forecasting
Advanced-Level Data Science Projects
1. Real-time Stock Price Prediction
- Dataset: Yahoo Finance API (Real-time stock data)
- Tools: Python, Scikit-learn, XGBoost, LSTM
- Description: Develop a real-time model to predict stock price movements using historical and live market data with machine learning and deep learning techniques.
- GitHub: Real-time Stock Price Prediction
2. Gesture Recognition System
- Dataset: ASL (American Sign Language) Dataset or custom video data
- Tools: OpenCV, TensorFlow, CNN, LSTM
- Description: Recognize hand gestures from video frames for sign language translation or human-computer interaction.
- GitHub: Gesture Recognition System
3. Resume Screening using Machine Learning
- Dataset: Collection of resumes (Custom or public datasets)
- Tools: NLP, SpaCy, Python, Scikit-learn
- Description: Automatically screen and rank resumes by extracting key skills, experience, and qualifications using natural language processing and ML classifiers.
- GitHub: Resume Screening
4. Fake News Detection
- Dataset: Kaggle Fake News Dataset
- Tools: TF-IDF, Logistic Regression, BERT
- Description: Detect and classify news articles as fake or real by analyzing textual content using classical ML and deep learning methods.
- GitHub: Fake News Detection
5. AI-Based Image Caption Generator
- Dataset: Flickr8k, MSCOCO
- Tools: CNN + LSTM, TensorFlow, Keras
- Description: Generate descriptive captions for images by combining convolutional neural networks for image processing and LSTM for language generation.
- GitHub: Image Caption Generator
6. Product Demand Forecasting
- Dataset: Retail sales data or Kaggle Retail Datasets
- Tools: Facebook Prophet, ARIMA, LSTM
- Description: Predict product demand trends and seasonal sales fluctuations to optimize inventory and supply chain management.
- GitHub: Product Demand Forecasting
7. Object Tracking in Videos
- Dataset: Custom video data or open datasets like MOTChallenge
- Tools: OpenCV, Deep SORT, TensorFlow
- Description: Track multiple objects in videos in real-time for surveillance or autonomous navigation using deep learning based tracking algorithms.
- GitHub: Object Tracking
8. Machine Learning-Based Chatbot
- Dataset: Custom Q&A pairs or datasets like Cornell Movie Dialogs
- Tools: NLTK, TensorFlow, Seq2Seq Models
- Description: Build an intelligent chatbot capable of understanding user queries and generating relevant responses using sequence-to-sequence deep learning.
- GitHub: ML Chatbot
9. Driver Drowsiness Detection
- Dataset: Eye blink datasets or real-time webcam data
- Tools: OpenCV, CNN, Haar Cascades
- Description: Detect driver fatigue by analyzing eye blink frequency and head pose to alert for drowsiness in real-time.
- GitHub: Driver Drowsiness Detection
10. Resume Ranking and Scoring System
- Dataset: Resume databases (Custom)
- Tools: NLP, Scikit-learn, Python
- Description: Develop a system that ranks and scores resumes based on predefined criteria like skills, experience, and education for efficient hiring processes.
GitHub: Resume Ranking System
Domain-Specific Machine Learning Projects
1. Medical Insurance Cost Prediction (Healthcare)
- Dataset: Medical Cost Personal Dataset (Kaggle)
- Tools: Python, Scikit-learn, Linear Regression
- Description: Predict individual medical insurance costs based on personal attributes like age, BMI, smoking status, and region.
2. Loan Default Prediction (Banking/Finance)
- Dataset: Lending Club Loan Data
- Tools: Python, XGBoost, Pandas
- Description: Binary classification model to predict whether a borrower will default on a loan using financial and demographic features.
- GitHub: Loan Default Prediction
3. Churn Prediction (Telecom/Retail)
- Dataset: Telco Customer Churn Dataset (Kaggle)
- Tools: Python, Random Forest, Scikit-learn
- Description: Predict customer churn by analyzing customer behavior and service usage patterns to improve retention strategies.
- GitHub: Customer Churn Prediction
4. Crop Yield Prediction (Agriculture)
- Dataset: Crop Production Data (FAO or Kaggle)
- Tools: Python, Random Forest, Time Series Models
- Description: Forecast crop yields based on historical weather, soil, and agricultural data to aid farmers and policymakers.
- GitHub: Crop Yield Prediction
5. Disease Outbreak Forecasting (Healthcare)
- Dataset: WHO or CDC Disease Surveillance Data
- Tools: Python, Time Series Forecasting, LSTM
- Description: Predict the spread and intensity of disease outbreaks such as flu or dengue using historical outbreak data and environmental factors.
- GitHub: Disease Outbreak Forecasting
6. Cyberbullying Detection (Social Media)
- Dataset: Twitter or Kaggle Cyberbullying Dataset
- Tools: NLP, BERT, Scikit-learn
- Description: Detect and classify cyberbullying content in social media posts using natural language processing and deep learning techniques.
- GitHub: Cyberbullying Detection
7. Personal Finance Dashboard with Predictive Analytics
- Dataset: Custom or Financial Transactions Data
- Tools: Python, Dash, Prophet
- Description: Build an interactive dashboard to track personal expenses and predict future spending and savings trends using ML.
- GitHub: Personal Finance Dashboard
8. Smart Traffic Prediction System (Smart Cities)
- Dataset: Traffic Flow Data (City Data Portals)
- Tools: Python, LSTM, TensorFlow
- Description: Predict traffic congestion and optimize routing using historical traffic sensor data and deep learning models.
- GitHub: Smart Traffic Prediction
9. Customer Lifetime Value Prediction (E-commerce)
- Dataset: Kaggle E-commerce Customer Data
- Tools: Python, Lifetimes Library, Scikit-learn
- Description: Estimate the total value a customer will bring over their relationship with a business to inform marketing and retention strategies.
10. Electricity Load Forecasting (Energy Sector)
- Dataset: Australian Energy Market Data
- Tools: Python, LSTM, Statsmodels
- Description: Forecast daily or hourly electricity load to help in energy grid management and demand response planning.
- GitHub: Electricity Load Forecasting
Unique & Cutting-Edge Machine Learning Projects

1. Human Activity Recognition with Smartphone Data
- Dataset: UCI HAR Dataset
- Tools: Python, Scikit-learn, Random Forest
- Description: Classify human activities such as walking, sitting, and standing using smartphone accelerometer and gyroscope sensor data.GitHub: Human Activity Recognition
2. Bird Species Identification from Images
- Dataset: Caltech-UCSD Birds-200-2011 (CUB-200-2011)
- Tools: TensorFlow, CNN, Transfer Learning
- Description: Classify bird species by analyzing images with deep convolutional neural networks using transfer learning techniques.
- GitHub: Bird Species Identification
3. Urban Sound Classification
- Dataset: UrbanSound8K
- Tools: Python, Librosa, CNN
- Description: Classify urban sounds like car horns, sirens, and dog barks using audio signal processing and deep learning.
- GitHub: Urban Sound Classification
4. Click-Through Rate Prediction (Ads)
- Dataset: Avazu CTR Prediction Dataset
- Tools: Python, XGBoost, LightGBM
- Description: Predict the likelihood that a user clicks on an advertisement to optimize digital marketing campaigns and ad placements.
- GitHub: CTR Prediction
5. YouTube Comment Toxicity Detection
- Dataset: Jigsaw Toxic Comment Classification Challenge (Kaggle)
- Tools: NLP, BERT, TensorFlow
- Description: Detect toxic comments on YouTube videos using transformer-based models to promote healthier online communities.
- GitHub: Toxic Comment Detection
6. Product Recommendation Engine (Collaborative Filtering)
- Dataset: Amazon Product Reviews
- Tools: Python, Surprise, Matrix Factorization
- Description: Build personalized product recommendation systems using collaborative filtering and matrix factorization techniques.
- GitHub: Product Recommendation System
7. Video Game Sales Prediction
- Dataset: Video Game Sales with Ratings (Kaggle)
- Tools: Python, Scikit-learn, Regression Models
- Description: Predict video game sales using historical sales data and ratings to guide development and marketing strategies.
- GitHub: Video Game Sales Prediction
8. Restaurant Success Prediction Based on Location & Reviews
- Dataset: Yelp Dataset
- Tools: Python, NLP, Geospatial Analysis
- Description: Predict the success of restaurants by analyzing location data, customer reviews, and ratings using machine learning and text analysis.
- GitHub: Restaurant Success Prediction
9. Legal Document Classification
- Dataset: LexGLUE Dataset
- Tools: NLP, BERT, HuggingFace Transformers
- Description: Classify legal documents into categories such as contracts, court rulings, or laws to improve legal research efficiency.
- GitHub: Legal Document Classification
10. Mental Health Detection via Survey & Behavioral Data
- Dataset: Mental Health in Tech Survey (Kaggle)
- Tools: Python, Scikit-learn, Logistic Regression
- Description: Detect potential mental health issues from survey and behavioral data to assist workplace wellness initiatives.
GitHub: Mental Health Detection
Domain-Based Projects (Finance, Healthcare, etc.)
This section presents data science projects segmented by industry. These are great for showcasing domain expertise and tailoring your resume for targeted roles.
Finance Projects
1. Credit Card Fraud Detection
- Tools: Python, Scikit-learn, XGBoost
- Dataset: Kaggle Credit Card Fraud Dataset
- Description: Detect fraudulent credit card transactions by analyzing transaction patterns using classification algorithms like XGBoost and Isolation Forest. This project helps financial institutions minimize losses by flagging suspicious activities in real-time.
2. Stock Price Prediction using LSTM
- Tools: Python, TensorFlow, Keras
- Dataset: Yahoo Finance API (historical stock prices)
- Description: Use Long Short-Term Memory (LSTM) networks to predict future stock prices based on historical price data. This time series forecasting project leverages deep learning to capture complex temporal dependencies in financial markets.
- Code: GitHub – Stock Price Prediction LSTM
- 3. Loan Default Prediction
- Tools: Python, Random Forest, XGBoost
- Dataset: LendingClub Loan Data
- Description: Predict whether a borrower is likely to default on a loan using historical data such as credit history, loan amount, and income. This project is essential for banks and fintechs to manage lending risks.
- Code: GitHub – Loan Default Prediction
- 4. Customer Segmentation in Banking
- Tools: KMeans, PCA, Tableau
- Dataset: UCI Bank Marketing Datase
- Description: Segment bank customers into meaningful groups using clustering techniques. This allows for personalized marketing strategies and customer relationship management.
- Code: GitHub – Customer Segmentation
Healthcare Projects

1. Disease Prediction from Symptoms
- Tools: Scikit-learn, Streamlit
- Dataset: Custom Symptoms Dataset
- Description: Build a web-based ML app that takes symptoms as input and predicts possible diseases. Useful for initial health screenings and remote diagnostics
2. COVID-19 Forecasting and Visualization
- Tools: Python, Pandas, Plotly
- Dataset: Johns Hopkins COVID-19 Dataset
- Description: Forecast and visualize the spread of COVID-19 using time series data. Create interactive graphs for cases, recoveries, and deaths by country.
3. Pneumonia Detection Using Chest X-rays
- Tools: TensorFlow, CNN, OpenCV
- Dataset: NIH Chest X-ray Dataset
- Description: Use deep learning to classify X-ray images into pneumonia-positive or normal cases. Helps automate diagnosis from medical images.
4. Health Insurance Claim Prediction
- Tools: Scikit-learn, XGBoost
- Dataset: Analytics Vidhya Health Insurance Dataset
- Description: Predict whether a customer will make a health insurance claim based on past patterns and demographics. Helps insurers optimize underwriting.
- Code: GitHub – Health Claim Prediction
E-commerce Projects
1. Product Recommendation System
Tools: Python, Surprise, LightFM
Dataset: Amazon Product Reviews, RetailRocket
Description: Build a collaborative and content-based filtering recommender system that suggests relevant products to users based on past behavior.
2. Sals Forecasting for an Online Retailer
Tools: Facebook Prophet, ARIMA
Dataset: UCI Online Retail Dataset
Description: Predict future sales using historical transaction data to help e-commerce businesses optimize inventory and supply chain decisions.
3. Customer Lifetime Value Prediction
Tools: Lifetimes Library, Python
Dataset: Kaggle E-commerce Dataset
Description: Estimate the total value a customer brings during their lifetime using probabilistic models, aiding in targeted marketing strategies
Code: GitHub – CLV Prediction
4. Sentiment Analysis on Customer Reviews
Tools: NLP, VADER, BERT
Dataset: Amazon Reviews
Description: Analyze customer sentiments (positive, negative, neutral) from reviews to improve product feedback analysis and customer service.
Education Projects

1. Student Dropout Prediction
- Tools: Python, Logistic Regression, Decision Trees
- Dataset: Open University Learning Analytics Dataset (OULAD)
- Description: Predict whether a student is likely to drop out based on behavioral and academic patterns. Helps institutions reduce dropout rates via timely interventions.
2. Adaptive Learning Path Recommendation
- Tools: Reinforcement Learning, Python
- Dataset: EdNet, Riiid Education Dataset
- Description: Build a personalized learning path recommender that adjusts course sequences based on learner performance and engagement.
3. Online Exam Cheating Detection
- Tools: Computer Vision, Facial Detection, ML
- Dataset: Custom Proctored Exam Data or Simulated Dataset
- Description: Use webcam feed and behavioral analysis to detect suspicious activity during online exams, aiding secure remote assessments.
4. MOOC Feedback Sentiment Analysis
- Tools: NLP, TextBlob
- Dataset: Course Review Platforms (Coursera, edX, Udemy – scraped or collected)
- Description: Perform sentiment analysis on student feedback from online learning platforms to enhance course design and instructional quality.
- Code: GitHub – MOOC Sentiment Analysis
Tool-Based Projects (Python, R, TensorFlow, etc.)
🐍 Python Projects

General Data Science & ML Projects
1. Movie Recommendation System
- Dataset: MovieLens Dataset
- Tools: Pandas, Scikit-learn
- Description: Developed a content-based movie recommendation engine using cosine similarity on movie genres and user ratings. Helps users discover movies similar to their preferences.
- GitHub: GitHub – Movie Recommender
2. Data Cleaning Pipeline
- Dataset: Titanic Dataset
- Tools: Pandas, NumPy
- Description: Created a reusable data preprocessing pipeline to handle missing values, encode categorical features, normalize data, and prepare datasets for machine learning models.
- GitHub: GitHub – Data Cleaning Pipeline
3. Exploratory Data Analysis Automation
- Dataset: Titanic, Iris (demo datasets)
- Tools: Pandas Profiling, Sweetviz
- Description: Automated the EDA process to generate visual, interactive reports for quick dataset exploration and hypothesis generation with minimal code.
- GitHub: GitHub – EDA Automation
R Projects
1. Customer Churn Prediction
- Dataset: Telco Customer Churn Dataset
- Tools: R, ggplot2, randomForest, caret
- Description: Developed a machine learning model to predict customer attrition using service usage patterns, tenure, and contract-related features. Included data preprocessing, feature selection, and model evaluation (accuracy, ROC).
- GitHub: GitHub – Churn Prediction in R
2. Market Basket Analysis
- Dataset: Groceries Dataset (arules)
- Tools: R, arules, arulesViz
- Description: Implemented association rule mining to uncover frequent product combinations and generate insights for cross-selling strategies. Visualized rules with interactive graphs and item frequency plots.
- GitHub: GitHub – Market Basket Analysis
TensorFlow Projects
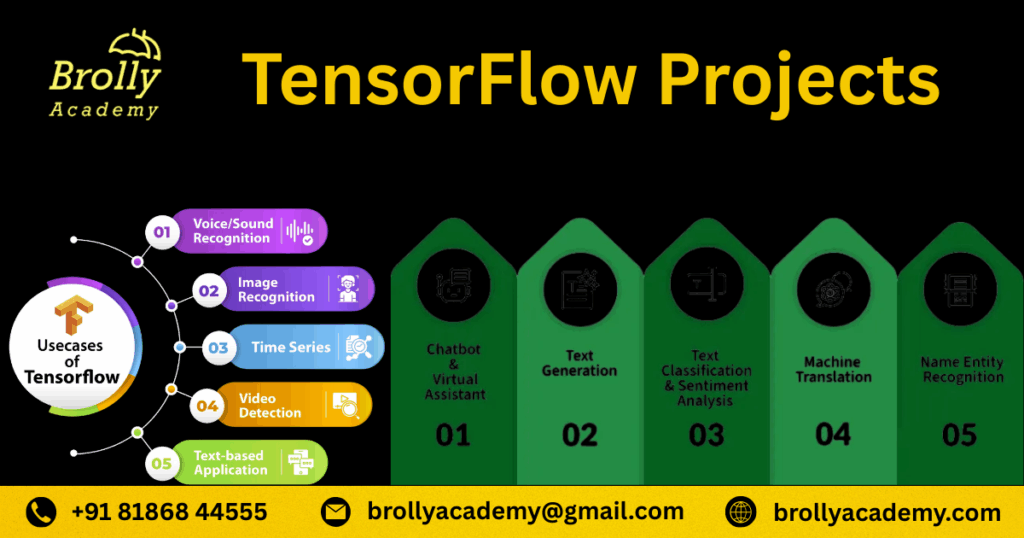
1. Handwritten Digit Recognition (MNIST)
Dataset: MNIST Handwritten Digits
Tools: TensorFlow, Keras, CNN
Description: Built a Convolutional Neural Network (CNN) to classify handwritten digits from the MNIST dataset. Achieved high accuracy through model tuning, dropout regularization, and data normalization. Suitable for beginners exploring deep learning image classification.
2. Image Caption Generator
Dataset: Flickr8k / Flickr30k
Tools: TensorFlow, CNN (InceptionV3), LSTM, Tokenizer
Description: Developed an image captioning model using an encoder-decoder architecture combining CNN for image feature extraction and LSTM for sequence generation. Trained on paired image-caption datasets to generate meaningful descriptions of images.
GitHub: GitHub – Image Caption Generator
Scikit-learn Projects
1. Titanic Survival Prediction
Dataset: Kaggle Titanic Dataset
Tools: Scikit-learn, Pandas, Seaborn
Description: Built a machine learning classification pipeline to predict survival of Titanic passengers based on features like age, class, gender, and fare. Applied preprocessing steps, feature engineering, and used models such as Logistic Regression and Random Forest with cross-validation.
2. Spam Detection (SMS Classifier)
Dataset: SMS Spam Collection Dataset
Tools: Scikit-learn, TfidfVectorizer, NLP
Description: Developed a text classification system to detect spam messages using natural language processing techniques. Employed TfidfVectorizer for text transformation and trained a Multinomial Naive Bayes classifier for efficient and accurate predictions.
GitHub: GitHub – Spam DetectionTableau Projects
1. Superstore Sales Dashboard
Dataset: Sample Superstore (Tableau Sample Data)
Tools: Tableau
Description: Built an interactive sales performance dashboard to analyze regional trends, segment-wise profits, product category performance, and shipping modes. Utilized filters and parameters for dynamic exploration by executives and sales teams.
Dashboard: View Dashboard
2. Global COVID-19 Tracker
Dataset: WHO / Johns Hopkins COVID-19 Time Series Dataset
Tools: Tableau
Description: Designed a global COVID-19 dashboard to track confirmed cases, recoveries, and death counts over time. Incorporated time sliders, country-wise filters, and heat maps for granular and real-time insights.
Dashboard: View Tracker
Portfolio & Career Tips
Creating data science projects is just the beginning. To turn your efforts into real career opportunities, you need to showcase them effectively. Here’s how to build a portfolio that impresses recruiters and hiring managers.
1. Build a Professional GitHub Profile
GitHub is the #1 platform recruiters check for data science credibility.
What to Include:
- Clean README: Each project should have a clear README with objective, tools used, dataset description, and results.
- Well-Structured Code: Use folders (/data, /notebooks, /scripts) to organize your files.
- Version Control: Commit frequently with meaningful messages.
Pro Tip:
Pin your top 6 projects using GitHub’s “Pinned Repositories” feature.
2. Showcase Projects on LinkedIn
LinkedIn is a discovery tool. If you’re not sharing your work here, you’re invisible to many recruiters.
How to Do It:
- Write mini case studies as posts.
- Use visuals: Add charts or dashboards as images.
- Tag relevant tools/skills: #machinelearning, #datascience, #python.
- Update your “Featured” section with GitHub links and blog posts.
3. Publish on Medium, Hashnode, or Dev.to
Written case studies boost your visibility and help with Answer Engine Optimization (AEO) and GEO standards.
What to Write:
- Your problem-solving process.
- Dataset preparation and challenges.
- Key algorithms used and why.
- Visuals, dashboards, and result interpretation.
Include outbound links to:
- GitHub repo
- Dataset source (Kaggle/UCI)
- Tools used (TensorFlow, Pandas, etc.)
4. Create a Personal Portfolio Website
Having your own portfolio site adds a professional edge and is great for SEO (especially GEO).
Platforms You Can Use:
- No-Code: Wix, Carrd, Notion
- Code-Based: HTML + Bootstrap, Jekyll (GitHub Pages)
Must-Have Sections:
- About Me
- Project Portfolio (link to GitHub & blogs)
- Resume (PDF download)
- Contact Info / LinkedIn / GitHub
5. Include Project Experience in Your Resume
Instead of just listing tools, demonstrate how you used them.
Example:
Stock Price Prediction using LSTM – Built a deep learning model in TensorFlow to forecast stock prices using time-series data from Yahoo Finance; achieved 92% accuracy.
Use quantifiable outcomes, highlight frameworks used, and match skills with job descriptions.
6. Tailor Your Portfolio to Job Roles
Not all roles are the same. Customize your pitch.
Role | What to Highlight |
Data Analyst | Dashboards, SQL, EDA, BI tools |
Data Scientist | ML models, NLP, Time Series |
ML Engineer | Model deployment, pipelines |
AI Engineer | Deep Learning, Computer Vision |
Business Analyst | Insights, storytelling, dashboards |
7. Engage with the Community
- Contribute to open-source data science repos.
- Participate in Kaggle competitions.
- Join forums (Reddit r/datascience, Stack Overflow, Discord groups).
FAQ’s
FAQs for Data Science Projects with Source Code
What are data science projects with source code?
→ Projects that solve real-world problems using data science techniques, with complete source code (often on GitHub) for learning and reuse.
Why are data science projects essential for learners?
→ They bridge theory and practice, help apply Python skills, and build job-ready portfolios—just like those taught at Brolly Academy.
Where can I find free source code for data science projects?
→ GitHub, Kaggle, Google Colab, and educational platforms like Brolly Academy.
How do I choose the right data science project?
→ Choose based on your skill level (beginner, intermediate, advanced) and goals (career, domain expertise, or tools).
Can I showcase open-source projects in interviews?
→ Yes. Personalized or forked projects from GitHub help you demonstrate problem-solving skills to recruiters.
What is the best data science project for a beginner?
→ Titanic dataset survival prediction using logistic regression is highly recommended.
Do I need Python knowledge to start?
→ Yes. Python is the primary language for most data science libraries and tools used in Brolly Academy’s projects.
What tools do I need to install?
→ Python, Jupyter Notebook, Pandas, NumPy, Matplotlib, and Scikit-learn.
Can I use Excel for data science?
→ Excel works for simple tasks, but Python or R is better for scalable analysis and modeling.
Which platform is easiest for beginners to run code?
Which Python libraries are used in most data science projects?
What is better: PyTorch or TensorFlow?
Which IDEs are best for data science projects?
Can I build and run projects on Google Colab?
→ Yes, and many projects from Brolly Academy include ready-to-run Colab notebooks.
Why should I use GitHub for my projects?
→ GitHub allows sharing, version control, collaboration, and builds a public portfolio.
What are good finance data science projects?
→ Credit card fraud detection, loan default prediction, and stock trend prediction.
Can I work on healthcare-related projects?
→ Yes—disease prediction, medical image classification, and patient risk scoring are impactful projects.
Are there education-based data science projects?
→ Yes—student performance prediction, dropout analysis, and online learning behavior analysis.
What e-commerce projects can I build?
→ Product recommendation systems, sales forecasting, and customer churn prediction.
Do domain-specific projects help in jobs?
→ Absolutely. Recruiters prefer portfolios with real-world, industry-aligned solutions—just like those taught at Brolly Academy.
Do data science projects help in getting hired?
→ Yes. Projects show hands-on skills, which employers value more than certifications alone.
How should I list my projects on a resume or LinkedIn?
→ Add title, tools, summary, challenges solved, results, and a GitHub link.
How many projects should I include in a portfolio?
→ 5 to 8 diverse, well-documented projects are ideal.
What should a good README file include?
→ Overview, dataset, tools used, step-by-step approach, results, and instructions to run the code.
Can I get freelance projects through GitHub?
→ Yes. A well-maintained GitHub with live projects (like those by Brolly Academy learners) attracts freelance and full-time offers.
What are some advanced data science projects?
→ Time-series forecasting, ensemble learning, GANs, and real-time dashboards.
How do I deploy a data science project?
→ Use Flask, FastAPI, Streamlit, Docker, and deploy to Heroku, AWS, or GCP.
What is a real-time data science project?
→ One that processes live data streams like stock prices or weather updates using Kafka or Spark.
Should I use AutoML in my projects?
→ Yes, tools like Google AutoML or H2O.ai help automate model selection and tuning.
What’s the difference between ML and DS projects?
→ ML projects focus on model performance. DS projects cover EDA, storytelling, modeling, and business impact.
Is this article optimized for Google’s AI Search and Answer Engine?
→ Yes. It includes structured data, headings, source code, FAQs, and optimized metadata.
What helps a data science article rank better on Google?
Can I turn data science projects into YouTube videos?
→ Absolutely. Brolly Academy encourages learners to explain their GitHub projects on YouTube to boost visibility.
Do these projects support Google SGE (Search Generative Experience)?
→ Yes. The projects include summaries, context-rich answers, and GitHub links to improve AI crawlability.
How can I make my data science profile more discoverable online?
→ Use proper keywords, public GitHub repos, schema.org markup, and contribute to platforms like Kaggle or Brolly Academy forums.